自从宅在家中后,养成了一个习惯:每周五全家一起在家中看一场电影。但每次在选择电影的时候都很耽误时间。于是就想到实现一个自动的程序,每周五下午的在各个影评的平台自动抓取本周热门电影,再发送消息/邮件给我,作为当晚要播放电影的参考。其实这个功能完全可以使用urllib来实现。不过下面使用Python中的爬虫框架Scrapy来实现。
## 安装并创建项目
首先安装Scrapy:
pip install Scrapy
接下来创建一个项目:
scrapy startproject douban
## 添加核心代码
### items.py
首先修改items.py:
import scrapy
class DoubanItem(scrapy.Item):
name = scrapy.Field()
可以看到DoubanItem类是scrapy.Item的子类。
### 使用Scrapy shell获取电影标题对应的路径
要想正确获取影片路径,需要使用浏览器的调试工具和Scrapy自带的命令行工具。
在浏览器中打开"https://movie.douban.com/"这个页面,在浏览器的开发者工具中查看:
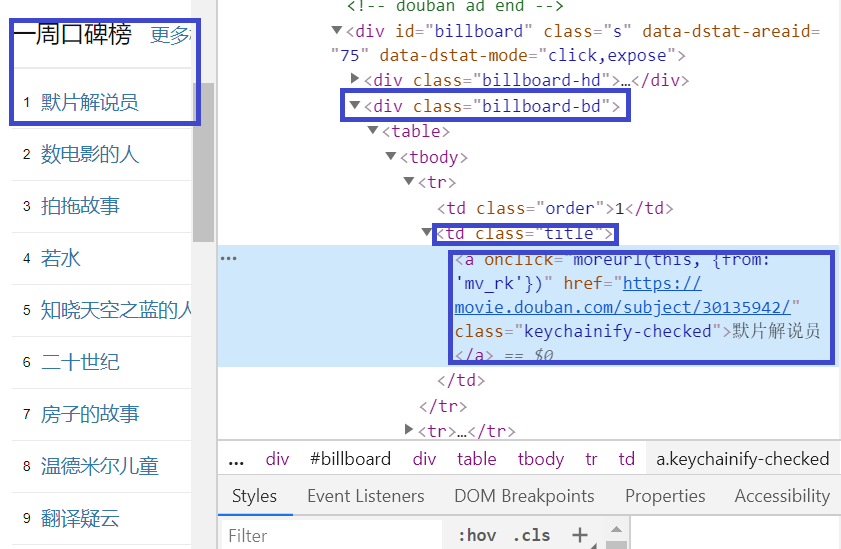
在下面的核心代码中,我们将使用
<div class="billboard-bd">
<td class="title">
<a>
标记来定位影片的标题。
### DoubanSpider
接下来编辑文件douban/spiders/douban_spider.py:
import scrapy
class DoubanSpider(scrapy.Spider):
name = "douban"
allowed_domains = ["https://movie.douban.com/"]
start_urls = [
"https://movie.douban.com/"
]
def parse(self, response):
movie_list = []
for movie in response.xpath("//div[@class='billboard-bd']//td[@class='title']/a/text()").getall():
movie_list.append(movie)
print(movie_list)
filename = "/var/tmp/movielist.txt"
with open(filename, 'w') as f:
f.write(str(movie_list))
DoubanSpider类继承自scrapy.Spider这个类。在上面的实现中重写了parse方法,自定义处理逻辑。
尝试运行一下:
scrapy crawl douban
从LOG中可以看到,豆瓣返回了一个403错误。这是由于其反爬虫机制导致的。
打开douban/settings.py,添加如下行:
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:77.0) Gecko/20100101 Firefox/77.0"
再尝试一下,成功!其输出类似于:
2020-06-26 15:49:34 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2020-06-26 15:49:35 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://movie.douban.com/robots.txt> (referer: None)
2020-06-26 15:49:35 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://movie.douban.com/> (referer: None)
['默片解说员', '数电影的人', '拍拖故事', '若水', '知晓天空之蓝的人啊', '二十世纪', '房子的故事', '温德米尔儿童', '翻译疑云', '乳牙']
上面这种方式根本就没有用到前面定义的items.py,如果想要使用的话,可以把douban_spider.py更改为:
import scrapy
class DoubanSpider(scrapy.Spider):
name = "douban"
allowed_domains = ["https://movie.douban.com/"]
start_urls = [
"https://movie.douban.com/"
]
def parse(self, response):
for movie in response.xpath("//div[@class='billboard-bd']//td[@class='title']/a/text()").getall():
yield {
'name': movie
}
需要注意的是,要想输出中文,需要在settings.py中添加:
FEED_EXPORT_ENCODING = 'utf-8'
再次运行:
scrapy crawl douban -o movies.json
其输出为:
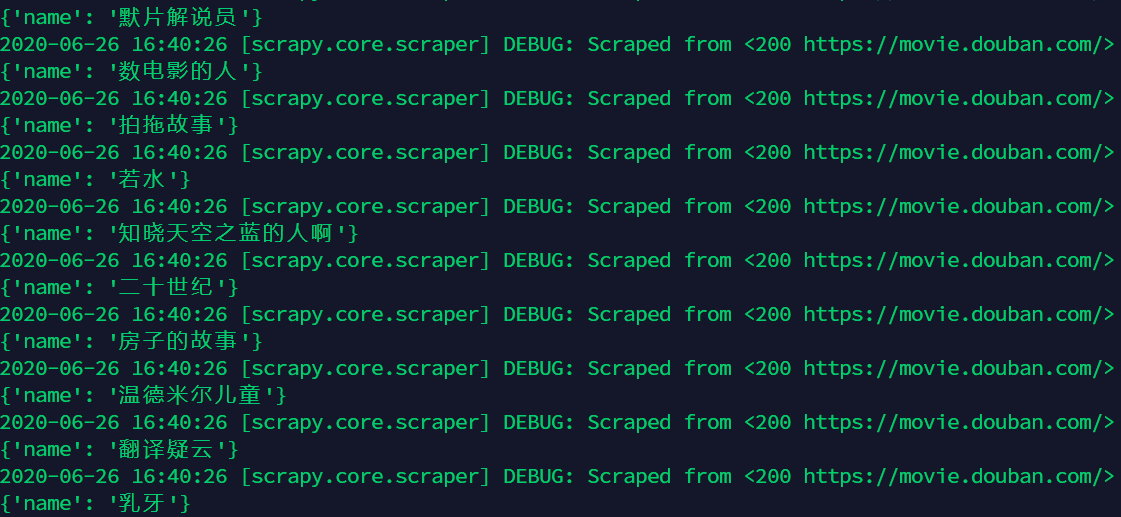
同样结果已经保存在json文件中。然后就可以把这些影片信息发送给自己了。利用同样的思路,可以获取其他影评网站的信息再汇总后一起发给自己。| author | aafeng |
|---|---|
| permlink | scrapy |
| category | hive-105017 |
| json_metadata | {"tags":["cn","cn-reader","cn-curation","cn-programming","python"],"image":["https://images.hive.blog/DQmPREtpb4dzg1KrsnmkqLhXPn2a3H2sADZwTCNaN92ivnV/image.png","https://images.hive.blog/DQmYXWujjXG8qc3Nv1ad9tftLH1VJNtPcNbcwwoVGj17Jv8/image.png"],"links":["https://movie.douban.com/"],"app":"hiveblog/0.1","format":"markdown"} |
| created | 2020-06-28 15:12:06 |
| last_update | 2020-06-29 10:55:33 |
| depth | 0 |
| children | 0 |
| last_payout | 2020-07-05 15:12:06 |
| cashout_time | 1969-12-31 23:59:59 |
| total_payout_value | 11.140 HBD |
| curator_payout_value | 9.986 HBD |
| pending_payout_value | 0.000 HBD |
| promoted | 0.000 HBD |
| body_length | 2,885 |
| author_reputation | 546,202,457,352,023 |
| root_title | 使用Scrapy自动获取豆瓣每周热门电影 |
| beneficiaries | [] |
| max_accepted_payout | 1,000,000.000 HBD |
| percent_hbd | 10,000 |
| post_id | 98,224,756 |
| net_rshares | 56,808,432,675,117 |
| author_curate_reward | "" |
| voter | weight | wgt% | rshares | pct | time |
|---|---|---|---|---|---|
| abit | 0 | 25,400,135,818,755 | 100% | ||
| wongshiying | 0 | 3,850,160,800 | 45.86% | ||
| mangou007 | 0 | 10,390,797,483 | 6.64% | ||
| gerber | 0 | 136,362,308,507 | 2% | ||
| ezzy | 0 | 156,499,552,800 | 2% | ||
| exyle | 0 | 199,023,897,030 | 2% | ||
| webdeals | 0 | 177,508,708,983 | 13.5% | ||
| tensaix2j | 0 | 1,818,411,010 | 45.86% | ||
| oflyhigh | 0 | 4,909,147,219,114 | 100% | ||
| bert0 | 0 | 31,483,187,152 | 6.64% | ||
| sweetsssj | 0 | 13,565,343,987,341 | 33% | ||
| someguy123 | 0 | 26,033,420,056 | 2% | ||
| cnfund | 0 | 100,397,819,329 | 45.86% | ||
| justyy | 0 | 390,111,995,804 | 45.86% | ||
| btshuang | 0 | 1,677,163,834 | 45.86% | ||
| bring | 0 | 60,870,666,726 | 100% | ||
| devilwsy | 0 | 1,526,771,738 | 45.86% | ||
| janiceting | 0 | 1,528,256,547 | 45.86% | ||
| elizacheng | 0 | 16,740,271,367 | 9% | ||
| privex | 0 | 3,613,299,882 | 4% | ||
| travelnepal | 0 | 3,810,076,211 | 22.93% | ||
| lordneroo | 0 | 5,788,974,340 | 29.1% | ||
| frankk | 0 | 9,987,296,525 | 10% | ||
| david777111 | 0 | 31,973,427,348 | 55% | ||
| dune69 | 0 | 6,793,581,271 | 2% | ||
| eliel | 0 | 55,421,529,398 | 30% | ||
| jerrybanfield | 0 | 19,837,738,195 | 2% | ||
| aleister | 0 | 5,097,702,705 | 10% | ||
| mys | 0 | 15,158,187,897 | 4.59% | ||
| guyverckw | 0 | 90,381,348,677 | 45.86% | ||
| improv | 0 | 3,023,062,241 | 4.5% | ||
| nuagnorab | 0 | 191,279,269,202 | 45.86% | ||
| linuslee0216 | 0 | 31,928,114,318 | 45.86% | ||
| wilkinshui | 0 | 63,629,222,340 | 45.86% | ||
| mxzn | 0 | 7,427,742,152 | 15% | ||
| aaronli | 0 | 57,972,912,973 | 45.86% | ||
| marylaw | 0 | 2,501,737,231 | 45.86% | ||
| shenchensucc | 0 | 24,857,189,884 | 45.86% | ||
| krischy | 0 | 16,174,181,763 | 36.68% | ||
| biuiam | 0 | 2,560,919,785 | 45.86% | ||
| techken | 0 | 30,540,149,335 | 50% | ||
| whd | 0 | 5,364,731,372 | 4.59% | ||
| d-pend | 0 | 7,843,425,208 | 0.3% | ||
| furious-one | 0 | 17,663,325,123 | 20% | ||
| gniksivart | 0 | 19,288,710,875 | 15% | ||
| susanli3769 | 0 | 167,259,922,929 | 100% | ||
| raili | 0 | 737,032,653 | 10% | ||
| runicar | 0 | 263,022,330,233 | 29.1% | ||
| davidmendel | 0 | 4,657,632,287 | 36.68% | ||
| rafalski | 0 | 569,097,365 | 4.59% | ||
| mrpointp | 0 | 31,926,834,510 | 45.86% | ||
| codingdefined | 0 | 52,136,637,185 | 18% | ||
| dado13btc | 0 | 971,247,490 | 29.1% | ||
| mygod | 0 | 1,674,865,691 | 45.86% | ||
| shitsignals | 0 | 667,457,044 | 2% | ||
| everrich | 0 | 4,313,015,742 | 45.86% | ||
| syh7758520 | 0 | 12,025,147,220 | 45.86% | ||
| diaohuijun | 0 | 3,085,855,477 | 45.86% | ||
| nicolemoker | 0 | 28,825,225,882 | 36.68% | ||
| stinawog | 0 | 4,816,299,094 | 30% | ||
| mangoanddaddy | 0 | 3,199,885,033 | 80% | ||
| aafeng | 0 | 248,521,059,565 | 100% | ||
| shihabieee | 0 | 1,778,731,549 | 16.5% | ||
| pardeepkumar | 0 | 60,822,297,453 | 29.1% | ||
| felander | 0 | 8,183,959,649 | 2% | ||
| karja | 0 | 198,884,157,945 | 10% | ||
| mrspointm | 0 | 38,461,099,591 | 45.86% | ||
| liumei | 0 | 5,698,601,597 | 45.86% | ||
| waiyee422 | 0 | 4,086,792,394 | 45.86% | ||
| fbslo | 0 | 1,621,994,660 | 2.29% | ||
| accelerator | 0 | 48,714,322,224 | 5% | ||
| yogacoach | 0 | 722,090,012 | 1% | ||
| estream.studios | 0 | 1,263,563,399 | 30% | ||
| veenang | 0 | 555,843,950 | 1.35% | ||
| chenlocus | 0 | 31,172,674,872 | 100% | ||
| rosatravels | 0 | 275,314,767,527 | 45.86% | ||
| deathwing | 0 | 2,022,040,373 | 2% | ||
| dancingapple | 0 | 4,822,924,690 | 20% | ||
| rakkasan84 | 0 | 1,441,320,654 | 24% | ||
| minloulou | 0 | 8,014,417,627 | 45.86% | ||
| victory622 | 0 | 185,225,509,264 | 97% | ||
| flamingirl | 0 | 1,687,249,549 | 6.64% | ||
| miti | 0 | 23,383,255,661 | 15% | ||
| jychbetter | 0 | 3,644,864,652 | 45.86% | ||
| winniex | 0 | 31,752,793,977 | 45.86% | ||
| caladan | 0 | 7,391,026,062 | 2% | ||
| cryptotradingfr | 0 | 5,121,165,333 | 10% | ||
| jianan | 0 | 1,478,453,345 | 45.86% | ||
| emrebeyler | 0 | 47,657,215,471 | 2% | ||
| windowglass | 0 | 1,841,070,295 | 45.86% | ||
| zmx | 0 | 5,887,046,243 | 45.86% | ||
| nileelily | 0 | 2,805,042,126 | 45.86% | ||
| jacktan | 0 | 1,320,287,913 | 22.93% | ||
| angelina6688 | 0 | 2,048,380,354 | 45.86% | ||
| lebin | 0 | 77,948,448,923 | 50% | ||
| iptrucs | 0 | 62,892,405,999 | 40% | ||
| elex17 | 0 | 1,805,221,118 | 100% | ||
| enjoyinglife | 0 | 7,168,420,406 | 29.1% | ||
| cheva | 0 | 9,280,824,761 | 45.86% | ||
| duke77 | 0 | 5,727,684,787 | 30% | ||
| adityajainxds | 0 | 16,171,839,346 | 30% | ||
| mmmmkkkk311 | 0 | 206,358,755,793 | 3.5% | ||
| nealmcspadden | 0 | 40,423,628,070 | 2% | ||
| maiyude | 0 | 1,471,869,906 | 45.86% | ||
| curx | 0 | 107,694,806,537 | 30% | ||
| culgin | 0 | 26,572,884,920 | 20% | ||
| purefood | 0 | 32,159,968,852 | 2% | ||
| enmaart | 0 | 15,951,456,979 | 15% | ||
| portugalcoin | 0 | 22,469,416,919 | 20% | ||
| gribouille | 0 | 2,188,859,849 | 50% | ||
| itharagaian | 0 | 29,738,026,762 | 100% | ||
| emmali | 0 | 6,661,305,454 | 45.86% | ||
| chronocrypto | 0 | 69,340,808,155 | 2% | ||
| kirato | 0 | 76,882,706,021 | 45.86% | ||
| mahtabansari370 | 0 | 23,874,586,848 | 14.55% | ||
| cadawg | 0 | 4,000,127,743 | 1.4% | ||
| kristves | 0 | 13,895,013,836 | 13% | ||
| nostalgic1212 | 0 | 36,950,535,927 | 45.86% | ||
| nenya | 0 | 537,225,517 | 72% | ||
| florenceboens | 0 | 1,078,243,310 | 10% | ||
| pkocjan | 0 | 866,925,694 | 1.6% | ||
| ofildutemps | 0 | 2,834,342,065 | 30% | ||
| sunrawhale | 0 | 30,238,804,192 | 30% | ||
| shentrading | 0 | 13,092,774,440 | 45.86% | ||
| mindtrap | 0 | 946,405,823,370 | 29.1% | ||
| also.einstein | 0 | 3,580,413,171 | 45.86% | ||
| ericet | 0 | 31,435,566,568 | 45.86% | ||
| josevas217 | 0 | 5,837,862,819 | 5.97% | ||
| beleg | 0 | 1,999,480,997 | 4.59% | ||
| bestboom | 0 | 7,686,808,266 | 2% | ||
| onepercentbetter | 0 | 3,488,483,979 | 1.5% | ||
| abrockman | 0 | 11,547,056,543 | 2% | ||
| aellly | 0 | 91,086,504,193 | 45.86% | ||
| huangzuomin | 0 | 6,291,989,675 | 45.86% | ||
| liewsc | 0 | 1,330,444,686 | 22.93% | ||
| tanzy | 0 | 611,107,795 | 22.93% | ||
| freddio | 0 | 21,128,569,306 | 15% | ||
| sustainablelivin | 0 | 1,630,197,453 | 15% | ||
| imcore | 0 | 1,024,526,772 | 10% | ||
| tresor | 0 | 18,863,965,992 | 6.64% | ||
| andrewma | 0 | 10,496,521,857 | 45.86% | ||
| softmetal | 0 | 4,836,108,676 | 45.86% | ||
| xiaoliang | 0 | 70,363,481,859 | 45.86% | ||
| i-d | 0 | 602,538,732,537 | 45.86% | ||
| steem.services | 0 | 1,300,521,897,269 | 30% | ||
| honoru | 0 | 201,587,654,751 | 45.86% | ||
| pladozero | 0 | 77,529,828,355 | 10% | ||
| nateaguila | 0 | 288,837,839,993 | 8% | ||
| hmayak | 0 | 10,565,617,664 | 45.86% | ||
| fishlucy | 0 | 13,305,980,453 | 50% | ||
| ronbong | 0 | 1,470,169,174 | 45.86% | ||
| merlion | 0 | 601,053,434 | 1.5% | ||
| robertyan | 0 | 7,300,416,684 | 45.86% | ||
| xiaoyuanwmm | 0 | 2,116,125,947 | 45.86% | ||
| kidsreturn | 0 | 2,373,553,345 | 45.86% | ||
| swisswitness | 0 | 1,140,323,272 | 2% | ||
| tydebbie | 0 | 3,501,966,545 | 22.93% | ||
| moneybaby | 0 | 15,598,789,947 | 45.86% | ||
| ybeyond | 0 | 2,168,452,124 | 45.86% | ||
| team-cn | 0 | 147,190,574,907 | 45.86% | ||
| milaan | 0 | 10,129,580,890 | 29.1% | ||
| wanggang | 0 | 16,232,044,210 | 9.17% | ||
| chick-fil-a | 0 | 1,494,063,994 | 45.86% | ||
| redlobster | 0 | 1,496,421,030 | 45.86% | ||
| fiveguys | 0 | 818,100,973 | 45.86% | ||
| marcoy2j | 0 | 1,309,412,094 | 45.86% | ||
| mastersa | 0 | 952,726,096 | 16.5% | ||
| bonefish | 0 | 1,491,305,819 | 45.86% | ||
| chilis | 0 | 1,502,788,708 | 45.86% | ||
| olive-garden | 0 | 788,751,807 | 45.86% | ||
| zhuanzhibufu | 0 | 2,689,812,521 | 100% | ||
| shine.wong | 0 | 1,653,966,164 | 45.86% | ||
| shuxuan | 0 | 1,511,786,048 | 45.86% | ||
| zhuxi | 0 | 2,685,877,314 | 100% | ||
| dlike | 0 | 25,361,028,762 | 2% | ||
| cryptoyzzy | 0 | 10,567,736,159 | 10% | ||
| melaniewang | 0 | 7,425,715,108 | 45.86% | ||
| teamcn-news | 0 | 790,464,365 | 45.86% | ||
| wenxuecity | 0 | 1,092,695,924 | 45.86% | ||
| mitbbs | 0 | 1,497,567,391 | 45.86% | ||
| gorbisan | 0 | 4,971,939,626 | 3.44% | ||
| rayshiuimages | 0 | 2,129,546,456 | 7.5% | ||
| artsymelanie | 0 | 25,131,461,916 | 45.86% | ||
| engrave | 0 | 25,565,635,937 | 1.9% | ||
| cercle | 0 | 2,256,638,032 | 100% | ||
| bobby.madagascar | 0 | 744,815,248 | 0.5% | ||
| slientstorm | 0 | 4,463,921,638 | 45.86% | ||
| laissez-faire | 0 | 20,280,929 | 100% | ||
| pet.society | 0 | 77,783,908,653 | 45.86% | ||
| minminlou | 0 | 727,365,781 | 34.39% | ||
| annepink | 0 | 72,501,923,135 | 45.86% | ||
| l-singclear | 0 | 2,539,373,742 | 100% | ||
| cherryzz | 0 | 141,099,683,558 | 45.86% | ||
| itharagaian.net | 0 | 2,181,876,840 | 100% | ||
| curart38 | 0 | 1,872,798,528 | 20% | ||
| teamcn-shop | 0 | 13,413,450,090 | 45.86% | ||
| yanyanbebe | 0 | 4,056,394,787 | 45.86% | ||
| memeteca | 0 | 828,317,941 | 6.64% | ||
| followjohngalt | 0 | 10,909,870,225 | 2% | ||
| vcs | 0 | 189,235,593,954 | 29.1% | ||
| quenty | 0 | 1,233,491,393 | 72% | ||
| kelvinzhang | 0 | 2,496,126,368 | 45.86% | ||
| starrouge | 0 | 597,896,646 | 30% | ||
| infinite-love | 0 | 1,842,686,209 | 30% | ||
| theskmeister | 0 | 39,489,880,857 | 100% | ||
| wherein | 0 | 509,248,513,892 | 60% | ||
| zerofive | 0 | 794,259,897 | 45.86% | ||
| jacuzzi | 0 | 4,244,765,562 | 7.5% | ||
| samsemilia7 | 0 | 7,217,342,170 | 40% | ||
| ahua | 0 | 946,236,589 | 45.86% | ||
| morningshine | 0 | 99,211,064,358 | 45.86% | ||
| cnstm | 0 | 180,268,769,556 | 60% | ||
| nimloth | 0 | 802,781,811 | 72% | ||
| likuang007 | 0 | 5,816,007,705 | 60% | ||
| cn-activity | 0 | 3,409,928,704 | 45.86% | ||
| davidchen | 0 | 32,258,694,093 | 45.86% | ||
| ajks | 0 | 506,664,141,448 | 29.1% | ||
| ctime | 0 | 371,824,101,674 | 3% | ||
| lianjingmedia | 0 | 560,477,503 | 60% | ||
| mia-cc | 0 | 2,909,824,196 | 22.93% | ||
| cecilian | 0 | 3,409,868,045 | 45.86% | ||
| hungrybear | 0 | 73,259,011 | 1.5% | ||
| devyleona | 0 | 13,480,713,908 | 45.86% | ||
| yanhan | 0 | 18,010,309,019 | 45.86% | ||
| foodiecouple | 0 | 3,239,265,660 | 45.86% | ||
| holydog | 0 | 16,557,267,045 | 45% | ||
| m18207319997 | 0 | 6,485,031,550 | 45.86% | ||
| lovelemon | 0 | 8,717,980,595 | 45.86% | ||
| theinspiration | 0 | 533,027,046 | 100% | ||
| epic4chris | 0 | 535,629,029 | 100% | ||
| cn-hello | 0 | 1,259,383,348 | 45.86% | ||
| bergelmirsenpai | 0 | 1,694,284,965 | 30% | ||
| mylord1992 | 0 | 3,448,754,514 | 45.86% | ||
| sirbush | 0 | 6,743,292,989 | 100% | ||
| aafeng.test | 0 | 554,971,375 | 100% | ||
| candy.tang | 0 | 11,905,052,540 | 100% | ||
| morwen | 0 | 143,688,612,173 | 72% | ||
| phillarecette | 0 | 2,885,117,522 | 12% | ||
| kgame | 0 | 1,528,556,536 | 45.86% | ||
| klima | 0 | 1,144,479,016 | 72% | ||
| hertz300 | 0 | 131,560,130,609 | 45.86% | ||
| koei | 0 | 1,026,577,519 | 45.86% | ||
| mosquito76 | 0 | 899,033,365 | 15% | ||
| nympheas | 0 | 8,274,496,658 | 36.68% | ||
| milu-the-dog | 0 | 863,276,754 | 2% | ||
| steem-drivers | 0 | 893,895,983 | 45.86% | ||
| triplea.bot | 0 | 678,424,350 | 2% | ||
| steem.leo | 0 | 49,841,912,591 | 2% | ||
| xiaoq.sports | 0 | 3,542,815,298 | 45.86% | ||
| freddio.sport | 0 | 3,930,790,775 | 15% | ||
| hykwf678233 | 0 | 16,243,057,863 | 45.86% | ||
| asteroids | 0 | 11,328,186,686 | 2% | ||
| atyh | 0 | 2,203,381,990 | 45.86% | ||
| botante | 0 | 37,124,828,847 | 15% | ||
| ericetchen | 0 | 803,728,805 | 45.86% | ||
| stevewu | 0 | 2,076,299,526 | 45.86% | ||
| kristinasiu | 0 | 828,233,914 | 45.86% | ||
| pukeko | 0 | 6,984,386,425 | 15% | ||
| maxuvd | 0 | 20,505,016,897 | 6% | ||
| trevorlp97 | 0 | 4,916,762,967 | 45.86% | ||
| btscn | 0 | 197,966,497,120 | 50% | ||
| trevormomo | 0 | 978,284,491 | 45.86% | ||
| freedomteam2019 | 0 | 1,860,873,490 | 20% | ||
| annzhao | 0 | 7,821,067,677 | 45.86% | ||
| cn-trail | 0 | 327,012,965 | 45.86% | ||
| gerbo | 0 | 0 | 2% | ||
| ladyalkaid | 0 | 707,230,325 | 45.86% | ||
| lnakuma | 0 | 5,537,956,821 | 45.86% | ||
| policewala | 0 | 24,570,369,638 | 15% | ||
| sacrosanct | 0 | 8,465,401,235 | 29.1% | ||
| roamingsparrow | 0 | 11,434,429,123 | 11.25% | ||
| ribary | 0 | 614,591,789 | 1% | ||
| kenchung1 | 0 | 15,606,528,135 | 45.86% | ||
| mice-k | 0 | 3,999,667,892 | 2% | ||
| ignet | 0 | 554,096,270 | 100% | ||
| steem.buzz | 0 | 1,080,894,331 | 45.86% | ||
| curamax | 0 | 577,353,951 | 1.5% | ||
| catanknight | 0 | 1,213,792,401 | 45.86% | ||
| steemcityrewards | 0 | 411,230,150 | 2% | ||
| dpend.active | 0 | 642,609,165 | 0.4% | ||
| lovequeen | 0 | 49,183,511,687 | 100% | ||
| bnk | 0 | 7,884,629,335 | 6.64% | ||
| polish.hive | 0 | 5,089,693,742 | 2% | ||
| littleksroad | 0 | 129,040,652,863 | 45.86% | ||
| dcityrewards | 0 | 54,691,984,581 | 2% | ||
| andrewmusic | 0 | 2,927,066,181 | 100% | ||
| portraits | 0 | 0 | 50% | ||
| kikoxixi | 0 | 11,647,984,011 | 45.86% | ||
| jywahaha | 0 | 398,872,968,123 | 45.86% | ||
| musiccccat | 0 | 220,209,846,068 | 45.86% | ||
| alwaysthinking | 0 | 6,815,371,513 | 45.86% | ||
| lithajacobs | 0 | 541,181,411 | 100% | ||
| hivecur | 0 | 5,110,554,007 | 2% | ||
| xiaomalailiao | 0 | 6,573,928,085 | 45.86% | ||
| weiweilove | 0 | 1,415,103,864 | 45.86% |