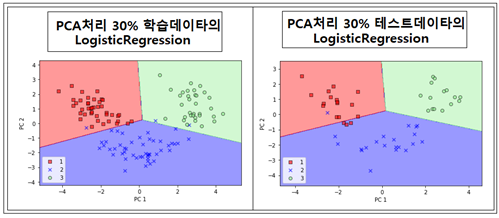
PCA를 통해 데이터의 차원이 13인 Wine 데이터의 주축을 2개 찾아 2차원 데이터로 만든 후 Logistic Regression Classification 결과가 우수하였다. Scikit-learn 라이브러리에서 지원하는 PCA 루틴을 사용하여 2차원 데이터를 생성한 후 Wine 데이타를 7:3 으로 학습용과 테스트용으로 나누어 Logistic Regression 에 의한 세부적인 인식률을 살펴보기로 하자.
파이선 코드 헤더 영역에 다음과 같이 필요한 라이브러리들을 불러들이자.
Pandas 데이터 프레임 방식으로 url 주소를 사용하여 wine 데이터를 불러와서 7:3으로 학습용과 테스트용으로 쪼갠 후 표준화 처리한다.
plot_decision_regions() 함수를 정의하여 차후에 Classifier 작업에서 얻어지는 결과에 대해 hyperplane 으로 분할되는 영역을 컬러로 작도하기로 하자. 이 함수를 파이선에서 scikit learn 공식 라이브러리로 편입하면 편리할텐데 매번 코딩작업 때 마다 루틴을 넣어줘야 하는 것이 조금 부담스럽다.
본론으로 들어가서 주축 수를 2로 설정하여 PCA 루틴을 불러낸 다음 학습용 데이터와 테스트용 데이터를 각각 표준화 처리하여 준비한다.
LogisticRegression 루틴을 불러 준비한 pca 데이터를 사용하여 학습을 시킨다.
테스트용 pca 데이터 즉 X-test_pca를 사용하여 인식작업 후 y_test 와 비교하여 인식률을 결정한다.
이어지는 루틴에서 학습 및 테스트 처리 결과를 그래픽 처리하여 출력한다.

PCA 처리된 학습용 데이터와 테스트 데이타 처리 결과를 살펴보자. 테스트 데이타에서는 4개의 샘플들이 잘못 처리되었으며 정밀도는 93% 수준이다.

거의 100년 전에 Pearson 에 의해 발명된 PCA 방법론에 의한 인식률이 93% 선의 정밀한 결과를 보여준다. 한편 동일한 wine 데이터를 시용하여 1936년에 Fisher 교수에 의해 고안된 LDA 기법에 의한 처리 결과와 비교해 보는 것도 매우 흥미롭다.
#pca_scikit_wine_01.py
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.model_selection import train_test_split
from matplotlib.colors import ListedColormap
from sklearn.linear_model import LogisticRegression
df_wine.columns = ['Class label', 'Alcohol', 'Malic acid', 'Ash',
'Alcalinity of ash', 'Magnesium', 'Total phenols',
'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins',
'Color intensity', 'Hue',
'OD280/OD315 of diluted wines', 'Proline']
df_wine.head()
#Splitting the data into 70% training and 30% test subsets.
X, y = df_wine.iloc[:, 1:].values, df_wine.iloc[:, 0].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3,
stratify=y,random_state=0)
#Standardizing the data.
sc = StandardScaler()
X_train_std = sc.fit_transform(X_train)
X_test_std = sc.transform(X_test)
def plot_decision_regions(X, y, classifier, resolution=0.02):
#setup marker generator and color map
markers = ('s', 'x', 'o', '^', 'v')
colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(y))])
#plot the decision surface
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution),
np.arange(x2_min, x2_max, resolution))
Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
Z = Z.reshape(xx1.shape)
plt.contourf(xx1, xx2, Z, alpha=0.4, cmap=cmap)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
#plot class samples
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=X[y == cl, 0],
y=X[y == cl, 1],
alpha=0.6,
c=cmap(idx),
edgecolor='black',
marker=markers[idx],
label=cl)
#Principal component analysis in scikit-learn
#Training logistic regression classifier
#using the first 2 principal components.
pca = PCA(n_components=2)
X_train_pca = pca.fit_transform(X_train_std)
X_test_pca = pca.transform(X_test_std)
lr = LogisticRegression()
lr = lr.fit(X_train_pca, y_train)
y_pred = lr.predict(X_test_pca)
print('\nPCA+LogisticRegression')
print('Misclassified samples: %d' % (y_test != y_pred).sum())
print('Accuracy: %.2f' % accuracy_score(y_test, y_pred))
print('Accuracy: %.2f' % lr.score(X_test_pca, y_test))
plot_decision_regions(X_train_pca, y_train, classifier=lr)
plt.xlabel('PC 1')
plt.ylabel('PC 2')
plt.legend(loc='lower left')
plt.tight_layout()
plt.show()
plot_decision_regions(X_test_pca, y_test, classifier=lr)
plt.xlabel('PC 1')
plt.ylabel('PC 2')
plt.legend(loc='lower left')
plt.tight_layout()
plt.show()
