**[Cyber•Fund](https://cyber.fund/)** is introducing a series of publications that provide an overview of some of the best speaker topics we’ve hosted at our [meetups](https://www.youtube.com/playlist?list=PLPWnfK03kxEDVJj4aPCdLDo--blBNm3iN). **Alexander Chepurnoy**—previously a core developer of Nxt, and most recently a founding member of [smartcontract.com](https://www.smartcontract.com/), [secureae.com](https://www.secureae.com/) and the [Scorex project](https://iohk.io/projects/scorex/)—he has over fifteen years of experience in software development. This was a particularly insightful lecture that is extremely beneficial to anyone wanting to understand in more detail about data structures and blockchain development.
# Hash Functions
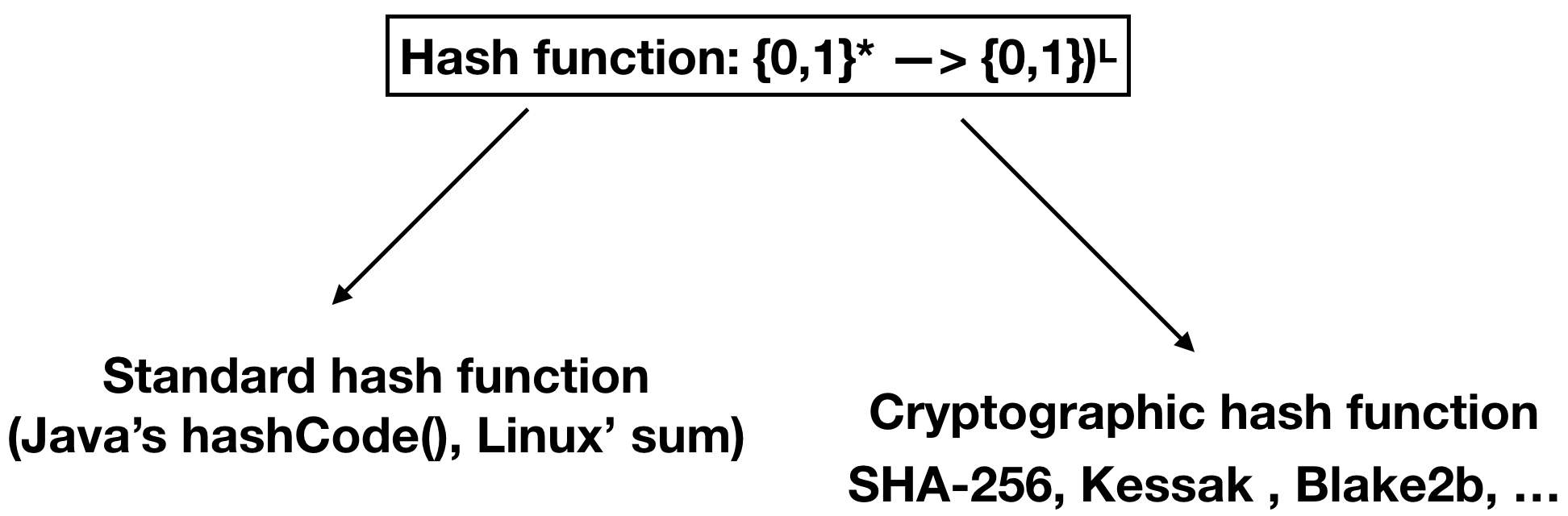
The above figure explains types of hash functions: the **standard hash function** and the **cryptographic function**. When dealing with the standard hash function collisions are acceptable. They should, however, be minimized because a violation is about efficiency. The cryptographic function should not present any collisions, even when dealing with an active attacker. This is due to the fact that: 1) the attacker is only limited by [probabilistic polynomial time](https://en.wikipedia.org/wiki/PP_(complexity)), 2) the attacker could hypothetically “win” as a result of **non-negligible probability**.
The standard definition of a cryptographic hash function is as follows: _“The output is a hash key that determines the randomness of the output. In theory, if the implementation is known, then the attacker can derive a collision and win the game.”_
S ← Gen(L)
H<sup>S</sup>(x): {0,1}<sup>L</sup>
Collision-resistance game H-Coll:
1. s ← Gen(L)
2. Adversary: x, x<sup>,</sup>
3. If H<sup>S</sup>(x) = H<sup>S</sup>(x<sup>,</sup>) & x≠x<sup>,</sup> return 1 else 0
For any PPT adversary, **PR[H-Coll(L)] ≤ negl(L)**
In other words:
* There is a key S with a length L. There is also a function of its generation ←, and the arrow to the left shows that the generation is random.
* There is a hash function that receives the generated key S and outputs a byte string of the same length L.
* The game is that we know S and we ask the Adversary to show x and x<sup>,</sup>. He wins if the hash of x=x<sup>,</sup> is under the condition x ≠ x<sup>,</sup>.
* The probability of an Adversary winning is almost zero.
According to Chepurnoy, “In such functions the input is of a finite size and functions that transfer a finite input of a specific length into an output of a particular smaller length are referred to as a compression function. Such functions are used in symmetric encryption algorithms, and block functions from **symmetric encryption algorithms** are used in hash functions.”
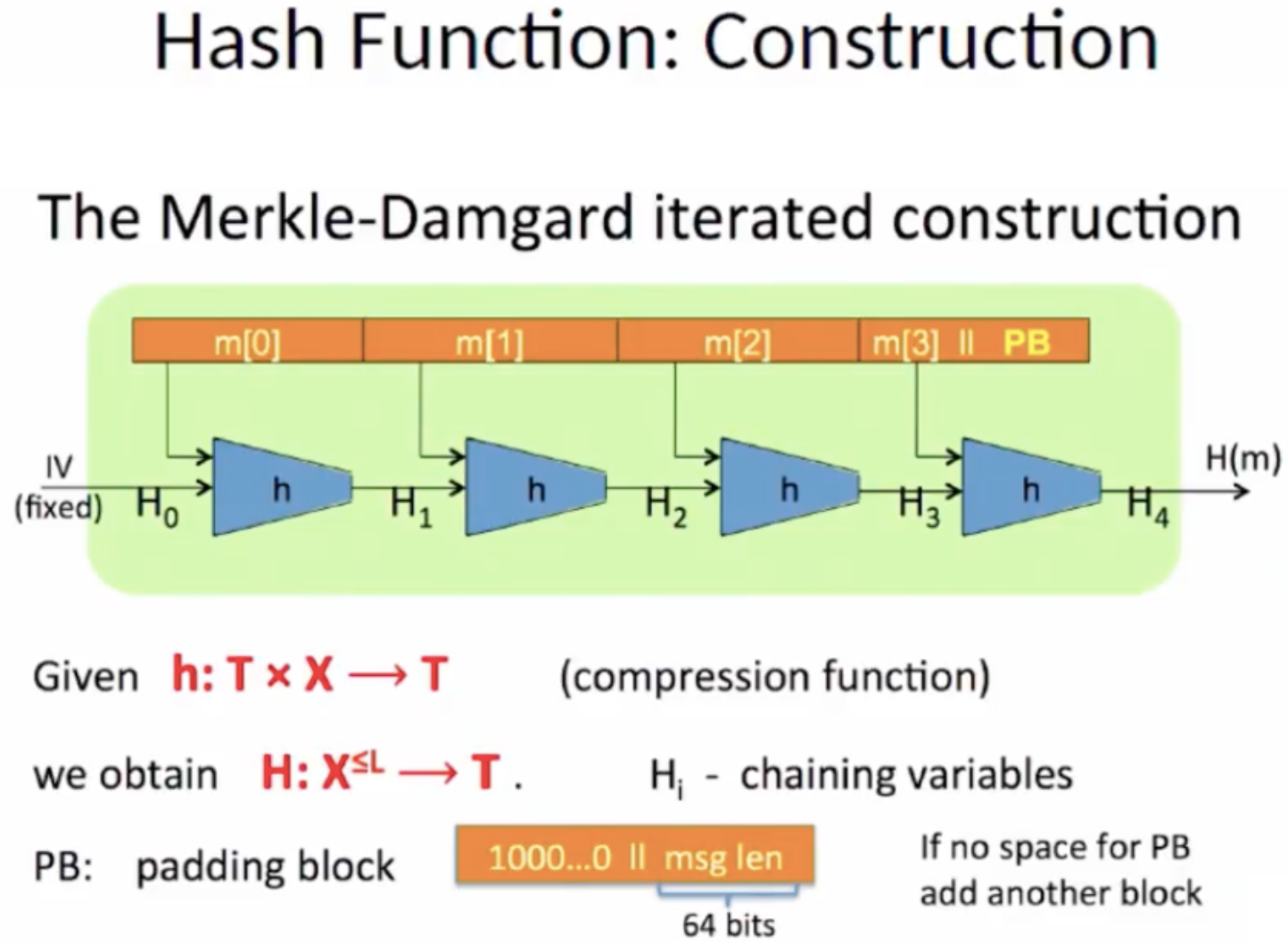
To compute the hash function of the message that is larger than the block size we need to add zeros to divide blocks by an integer number. There is a certain constant in the standard and we submit it to the input of the block, which computes the hash. Then we take the first block, compute the value of the first hash and put it into the second block. This continues until we calculate the entire hash function. This hash function accepts an argument of any size for input, and the output is a value equal to the hash size of the function of one block.
# Hashchains
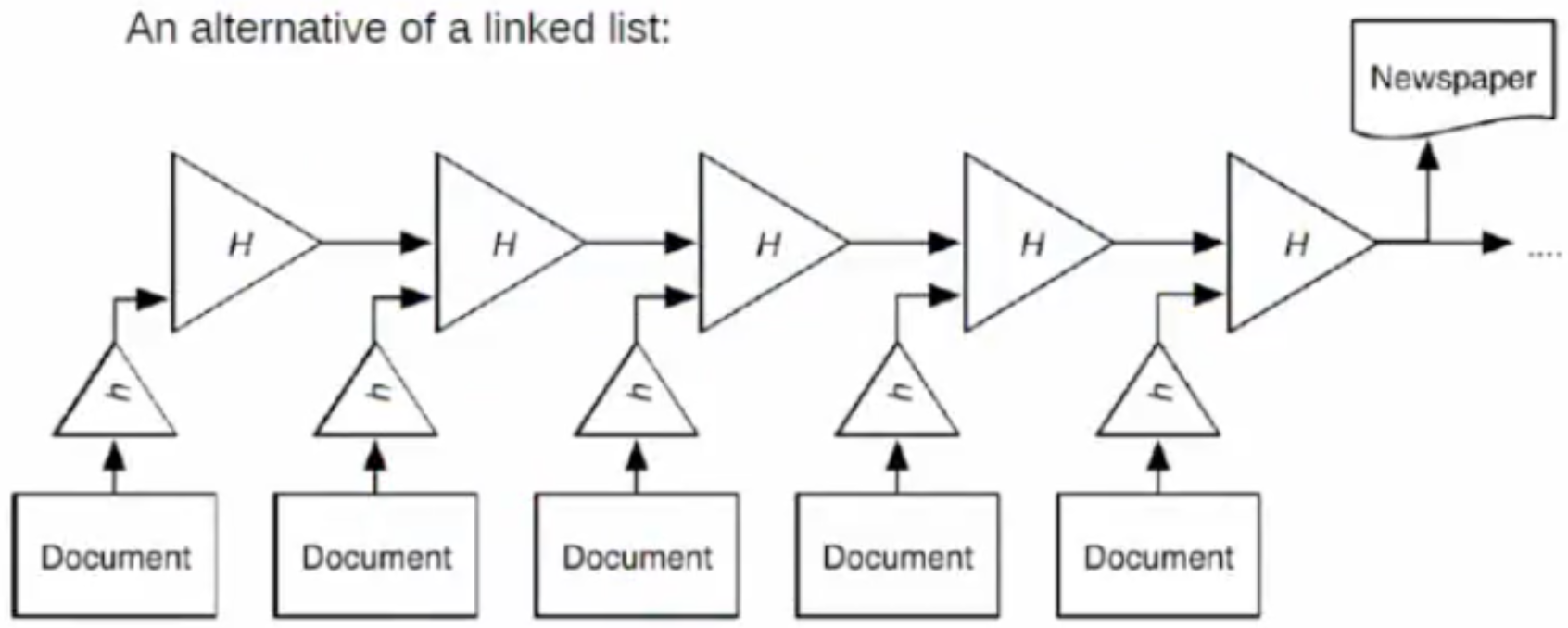
The above figure illustrates the hash function that can be called the **early prototype Blockchain**. As Chepurnoy explained, the hashchain functions as follows: “The hash of the first document (h) is calculated and goes to the hash function (H), then the output of this hash function together with the hash of the next document goes to the hash function of the second level and so on. The output is a hash that certifies all documents.”
The main disadvantage of this structure is that you need to check all the documents in the chain if you want to verify the validity of a single document. The Merkle tree solves this problem.
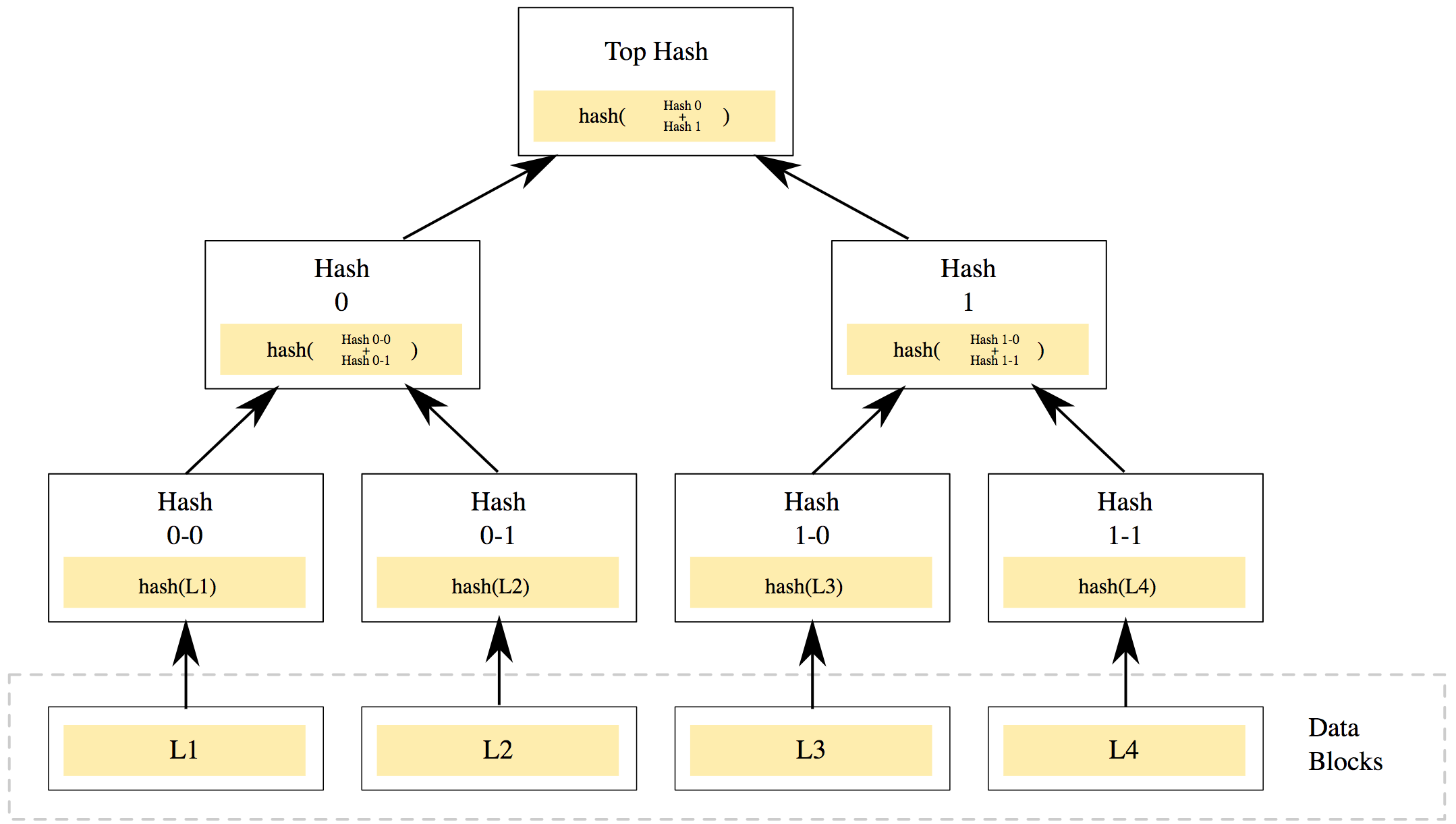
The Merkle tree is originally a perfectly balanced tree and the number of elements, or leaves, is two. Chepurnoy explained that in order to obtain a single hash that is stored in the archive, “we consider hashes from all four documents. Then we group the hashes into two and the number of such pairs will be even; at the bottom are two. We then consider hashes from two blocks, and as a result we get two nodes that are on the second level. From them we are able to compute the hash and get a root hash.”
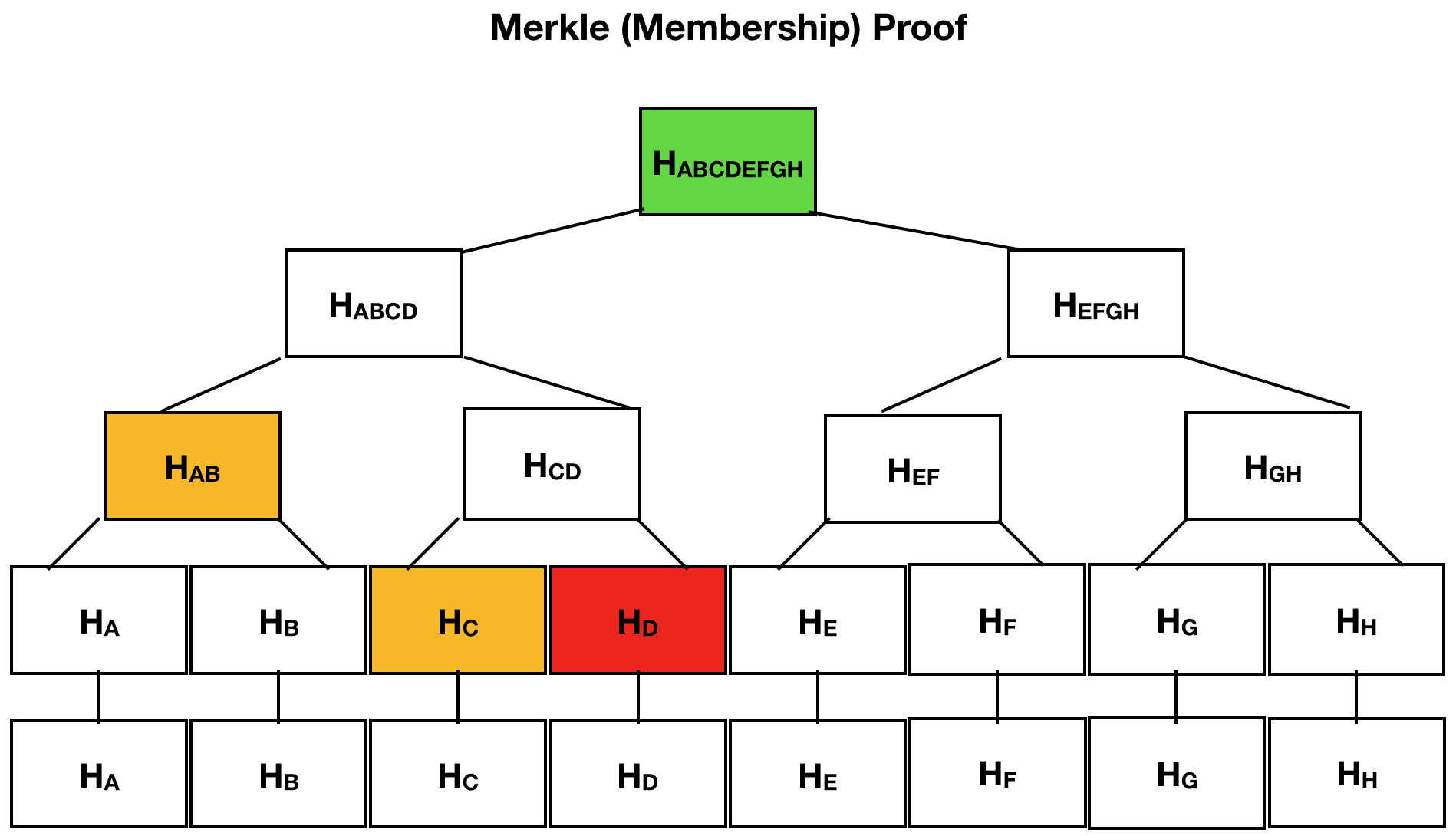
The Merkle membership proof allows us to effectively prove the existence of one node, as long as we know the archived hash. For example, to prove the existence of document D, it is necessary to identify the nodes marked with yellow. The node marked in red is an inspector and should not be presented. You can calculate these nodes and compare them with the root, and if the values match, then the document is in the tree. The size of the proof is the logarithm of the number of leaves, or the height of the tree.
# Merkle tree in Bitcoin
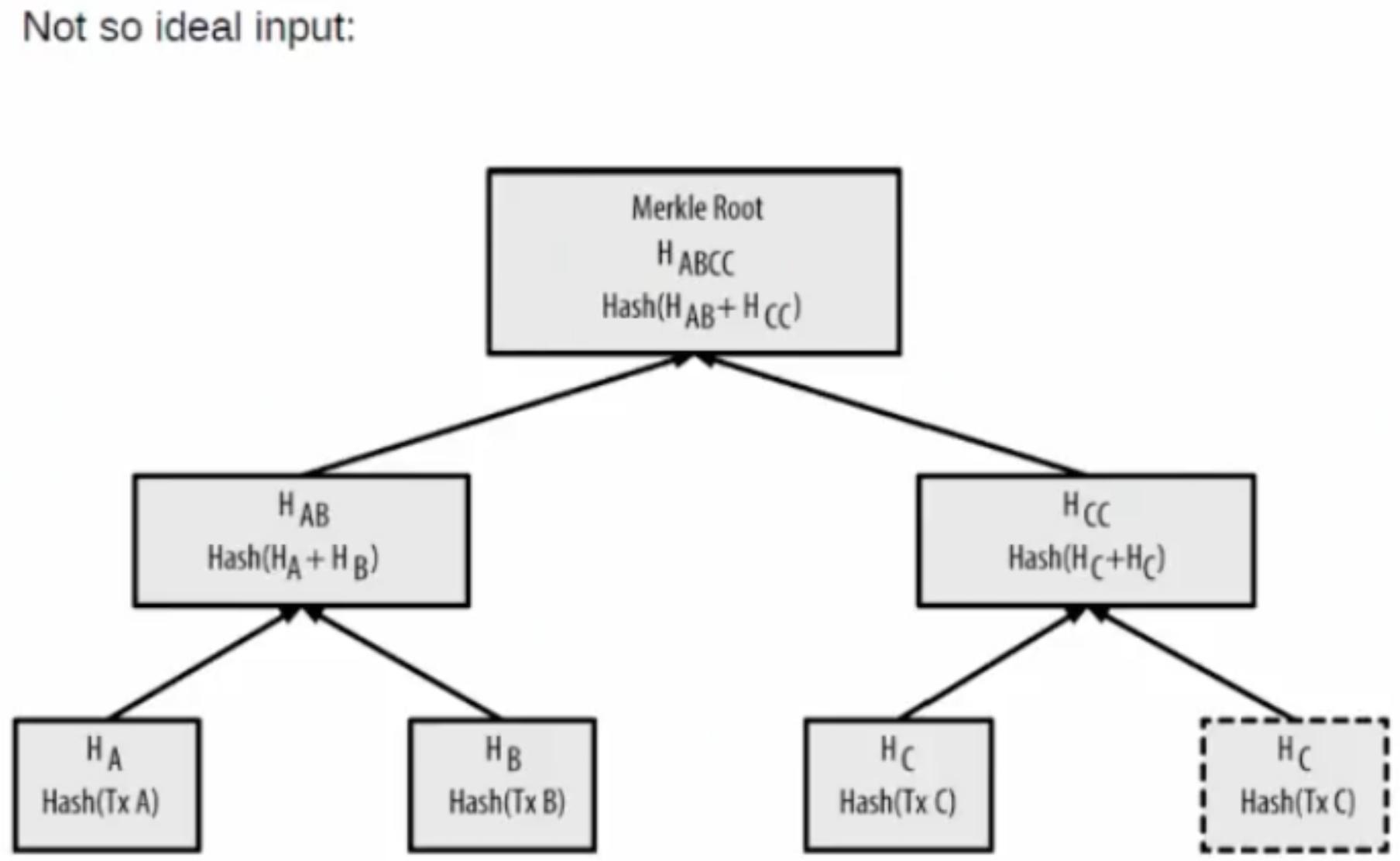
The Merkle tree is used in Bitcoin to confirm the existence of transactions in the block. The tree in Bitcoin is built based on the same principle. The main difference, however, is that the number of transactions in the block is not to the degree of two. Subsequently, the last transaction in Bitcoin is duplicated until it reaches the degree of two. Keeping this in mind, it is clear that the Merkle tree in Bitcoin is not effective and presents a few issues: the set of transactions at the bottom of the tree can be changed, the number of elements or height of the tree are not included and the tree is more vulnerable to collisions. The Merkle tree is intended to be used for a statistical, unordered set. It is simple, but easy to compute incorrectly. For these reasons Chepurnoy advised against the use of Bitcoin’s tree, and further suggested the use of **domain separation** to avoid passing a number of elements along with the root hash.
For more information please contact: **pr@cyberfund.io**