pixabay
https://cdn.pixabay.com/photo/2019/05/14/17/07/web-development-4202909_1280.png
[지난 시간](https://steemit.com/hive-101145/@june0620/python-13-django-6)에 구현한 검색을 좀 더 다듬어 봤다. 사용하다 보니 문제가 보였기 때문이다. tag, title, body 값을 모두 넣으면 조건에 맞는 모든 결과가 검색되는데 생각해보니 내가 의도한 바와는 조금 다르다. 즉 tag or title or body로 연산된 것.
보통 이 세 개값을 동시에 사용하여 검색할 경우, tag가 포함된 글목록에서 title 혹은 body값이 포함되어 있는 글을 추가로 검색하기 위해서다. 즉 tag and (title or body).
그럼 바꿔보자. 바꾸는 김에 python의 클래스로 구현해 보자. 아직까지 클래스가 어떤 점에서 더 좋은지는 모르겠지만 일단 해보자. (#python초보#어렵다어려워)
##### services.py
1. 검색 클래스를 services.py 내에 생성 후 전역 변수 account, q_titles, q_texts, q_tags, blogs 설정
2. __init__ 함수로 기본 인자 query를 dict으로 설정 및 전역변수에 값 할당
3. search_posts 함수에 검색 기능 추가. tag 값이 없거나 혹은 매칭 되는 값이 있을 경우에만 추가로 title 혹은 body 값 체크, 값이 매칭될 경우 새 list에 추가
4. title과 body 값 체크는 하나의 함수에 넣기에 가독성이 떨어지므로 is_keywords_contains로 분리
5. 글의 태그 값 추출을 위한 get_tags 함수 생성
```
import json
from steem import Steem
class Search:
s = Steem()
account = 'june0620'
q_titles = []
q_texts = []
q_tags = []
blogs = []
def __init__(self, query: dict):
self.q_titles = query['titles']
self.q_texts = query['texts']
self.q_tags = query['tags']
self.blogs = self.s.get_blog(self.account, 0, 400)
def search_posts(self):
s_blogs = []
for blog in self.blogs[:]:
blog_data = blog['comment']
title = blog_data['title'].lower()
body = blog_data['body'].lower()
tags = self.get_tags(blog_data['json_metadata'])
if not self.q_tags or set(self.q_tags) & set(tags):
if self.is_keywords_contains(title, body):
s_blogs.append(blog)
return s_blogs
def is_keywords_contains(self, title: str = [], body: str = []):
if any(q_title in title for q_title in self.q_titles):
return True
if any(q_text in body for q_text in self.q_texts):
return True
return False
def get_tags(self, json_metadata: str):
metadata = json.loads(json_metadata)
if metadata:
return metadata['tags']
else:
return []
```
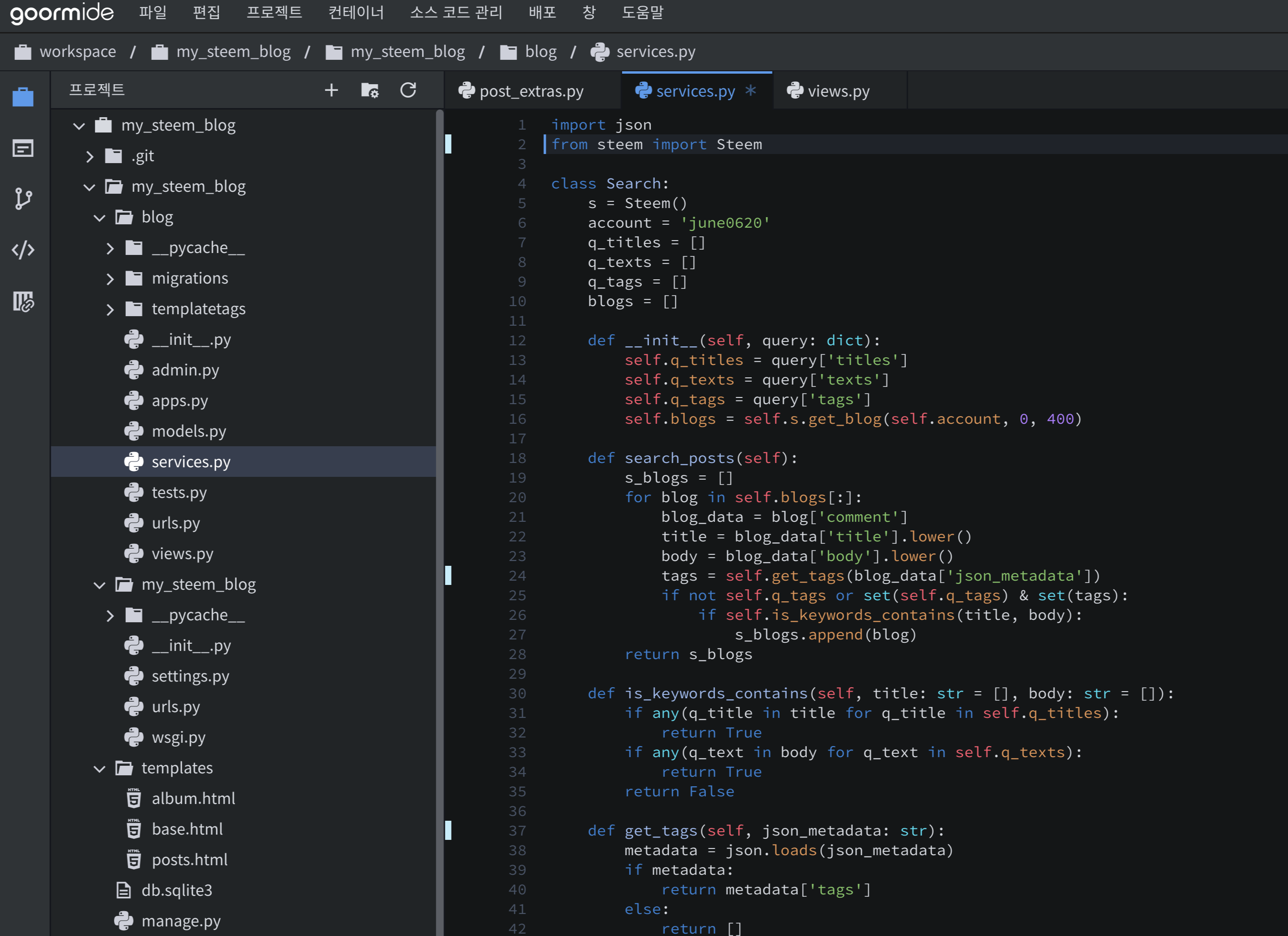
##### views.py
django의 ListView를 상속받아 queryset에 검색된 목록을 넣어주고 html에 뿌려준다.
```
from django.http import HttpResponse
from django.views.generic import ListView
from .services import Search
from steem import Steem
s = Steem()
def main_view(request):
data = s.get_account('june0620')
response = HttpResponse()
response.write(data)
return response
class posts(ListView):
template_name = 'album.html'
context_object_name = 'all_posts'
def get(self, request, *args, **kwargs):
# self.queryset = s.get_blog(kwargs['account'], entry_id=0, limit=100)
query = {
'tags': ['kr'],
'titles': ['python'],
'texts': ['사랑하겠습니다']
}
se = Search(query=query)
self.queryset = se.search_posts()
return super().get(request, *args, **kwargs)
```
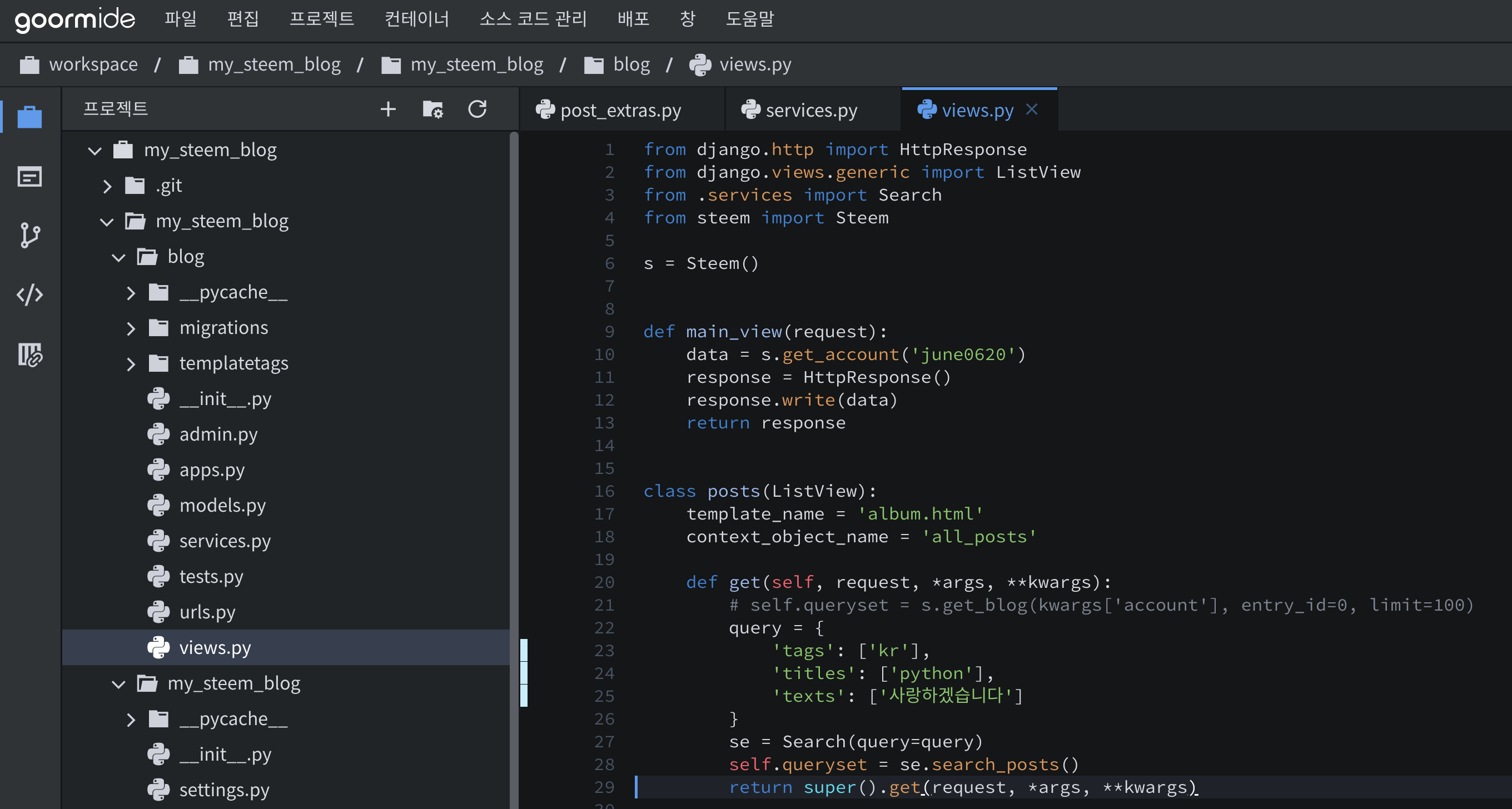
##### Results
간단하게 테스트해보니 잘 되는 듯하다. (나중에는 django의 test 기능도 좀 써봐야겠다.)
***
**[Cookie 😅]**
Python 3.7.4
Django 2.2.4
steem-python 1.0.1
goorm IDE 1.3| author | june0620 |
|---|---|
| permlink | python-14-django-7-2 |
| category | hive-132971 |
| json_metadata | {"app":"peakd/2020.08.3","format":"markdown","tags":["kr","dev","whalepower","dblog","palnet","python","goorm"],"users":["june0620"],"links":["https://steemit.com/hive-101145/@june0620/python-13-django-6"],"image":["https://cdn.pixabay.com/photo/2019/05/14/17/07/web-development-4202909_1280.png","https://cdn.steemitimages.com/DQmbEpGTwUDzwmECJT12w2fQgpTKERTYcUUJQM34jENqCjM/image.png","https://cdn.steemitimages.com/DQmbXLZvspSFdpEbstMw34PAQa3P8MmFWBiFamLDSrGvDGm/image.png","https://cdn.steemitimages.com/DQmUdGzz9HsnXQKMK3ZDnLf7gpYmWkCTJQKU31RqUCxXzZg/image.png"]} |
| created | 2020-08-29 06:21:12 |
| last_update | 2020-08-29 06:21:12 |
| depth | 0 |
| children | 0 |
| last_payout | 2020-09-05 06:21:12 |
| cashout_time | 1969-12-31 23:59:59 |
| total_payout_value | 0.970 HBD |
| curator_payout_value | 0.866 HBD |
| pending_payout_value | 0.000 HBD |
| promoted | 0.000 HBD |
| body_length | 3,438 |
| author_reputation | 118,592,211,436,406 |
| root_title | "[Python #14] [Django #7] 내 포스팅 검색 #2" |
| beneficiaries | [] |
| max_accepted_payout | 1,000,000.000 HBD |
| percent_hbd | 10,000 |
| post_id | 99,334,558 |
| net_rshares | 6,423,921,912,876 |
| author_curate_reward | "" |
| voter | weight | wgt% | rshares | pct | time |
|---|---|---|---|---|---|
| slowwalker | 0 | 63,358,035,584 | 50% | ||
| livingfree | 0 | 315,823,457,021 | 4% | ||
| tumutanzi | 0 | 553,105,151 | 50% | ||
| oldstone | 0 | 21,876,304,196 | 50% | ||
| koskl | 0 | 25,843,009,827 | 100% | ||
| created | 0 | 661,266,798,935 | 4% | ||
| coldhair | 0 | 892,445,338 | 50% | ||
| lotusofmymom | 0 | 500,806,352 | 50% | ||
| alphacore | 0 | 6,391,763,450 | 0.65% | ||
| shenchensucc | 0 | 18,031,703,928 | 30% | ||
| khaiyoui | 0 | 463,268,060,000 | 21% | ||
| kimzwarch | 0 | 8,633,863,718 | 4% | ||
| june0620 | 0 | 538,131,903,734 | 100% | ||
| minloulou | 0 | 2,699,801,595 | 10% | ||
| lindalex | 0 | 580,349,302 | 50% | ||
| cnbuddy | 0 | 919,442,136,852 | 100% | ||
| itchyfeetdonica | 0 | 52,497,360,015 | 50% | ||
| nokodemion | 0 | 11,917,950,841 | 100% | ||
| suhunter | 0 | 961,902,227 | 50% | ||
| udabeu | 0 | 9,026,889,279 | 30% | ||
| jsj1215 | 0 | 5,020,408,976 | 100% | ||
| yasu | 0 | 6,765,103,042 | 100% | ||
| futurecurrency | 0 | 27,086,415,182 | 37% | ||
| realprince | 0 | 36,278,447,422 | 100% | ||
| gghite | 0 | 244,837,130,716 | 100% | ||
| quochuy | 0 | 101,317,219,856 | 7.23% | ||
| payroll | 0 | 90,409,549,524 | 2% | ||
| julialee66 | 0 | 1,107,627,165,647 | 8.5% | ||
| andrewma | 0 | 11,531,876,368 | 50% | ||
| wisdomandjustice | 0 | 1,420,577,543 | 50% | ||
| suonghuynh | 0 | 13,063,435,011 | 6% | ||
| coder-bts | 0 | 4,593,460,378 | 50% | ||
| daath | 0 | 855,244,406 | 100% | ||
| smartvote | 0 | 133,606,490,496 | 6% | ||
| veronicalee | 0 | 716,462,711 | 50% | ||
| melaniewang | 0 | 8,166,680,113 | 50% | ||
| changxiu | 0 | 5,053,333,843 | 50% | ||
| laissez-faire | 0 | 107,879,620 | 100% | ||
| cherryzz | 0 | 159,558,772,194 | 50% | ||
| forecasteem | 0 | 79,339,054,071 | 100% | ||
| moneytron | 0 | 7,676,804,965 | 100% | ||
| ctime | 0 | 784,184,910,840 | 5% | ||
| cpt-sparrow | 0 | 4,817,952,253 | 100% | ||
| tina3721 | 0 | 4,865,573,237 | 50% | ||
| andyhsia | 0 | 7,666,458,892 | 100% | ||
| minigame | 0 | 345,285,014,940 | 100% | ||
| oldstone.sct | 0 | 600,315,403 | 50% | ||
| hongdangmu | 0 | 549,125,854 | 8.5% | ||
| cnbuddy-reward | 0 | 73,935,700,756 | 100% | ||
| roseofmylife | 0 | 3,552,692,946 | 50% | ||
| real3earch | 0 | 9,190,090,153 | 100% | ||
| steem-agora | 0 | 11,160,299,642 | 50% | ||
| toni.pal | 0 | 0 | 0.52% | ||
| hiveyoda | 0 | 11,003,915,245 | 4% | ||
| blogstats | 0 | 380,703,286 | 100% |