<div class="text-justify">

<center>[Image Source](https://www.linkedin.com/pulse/pandas-dataframe-functions-madhavan-vivekanandan)</center>
In the last [post](https://hive.blog/hive-196387/@leoumesh/intro-to-pandas-library-python), I gave a brief introduction to pandas library and one of its main data structure which is series. In this post, I am going to briefly talk about another data structure which is DataFrames. DataFrame is used to store data in two dimensional form, or in another word-tabular form in terms of rows and columns. Rows are used to store the information while columns are used to label the information. DataFrame can also be said as a collection of series as I discussed in my previous post. There are many things you can do with pandas dataframes like manipulating the data which includes indexing, merging, sorting, redefining the data like modifying, adding or deleting rows/column, cleaning and preparing the data by filling the null or NaN values, and so on.
Dataframe makes it easier for data to be used for visualization and analysis purposes. And the best things about pandas is that it supports most of the file extensions type like JSON, plain text, CSV and so on. Here we will do some coding related to DataFrame. The syntax for creating a DataFrame is quite similar to that of series. We will create a weather dataframe that contains 5 data about date, city, temperature, humidity and precipitation value for particular US cities.
```
import pandas as pd
row_labels = [0,1,2,3,4]
column_labels = ['Date', 'City', 'Temperature', 'Humidity', 'Precipitation (in mm)']
data = [['2024-01-01', 'New York', 30, 80, 0.2],
['2024-01-02', 'Los Angeles', 60, 65, 0.0],
['2024-01-03', 'Chicago', 25, 78, 0.1],
['2024-01-04', 'Houston', 50, 60, 0.4],
['2024-01-05', 'Phoenix', 45, 55, 0.3]]
df = pd.DataFrame(index=row_labels, data=data, columns = column_labels)
df
```
So you may have seen above at first we imported pandas library and then define labels for column and rows. Then we filled the data for each of the 5 columns for 5 US cities. Then we used ***DataFrame*** function to create a dataframe which takes some argument like index itself, the row, columns and the data. There is an optional argument that you can pass here which is a ***datatype (dtype)***. Now lets see the output in tabular format.
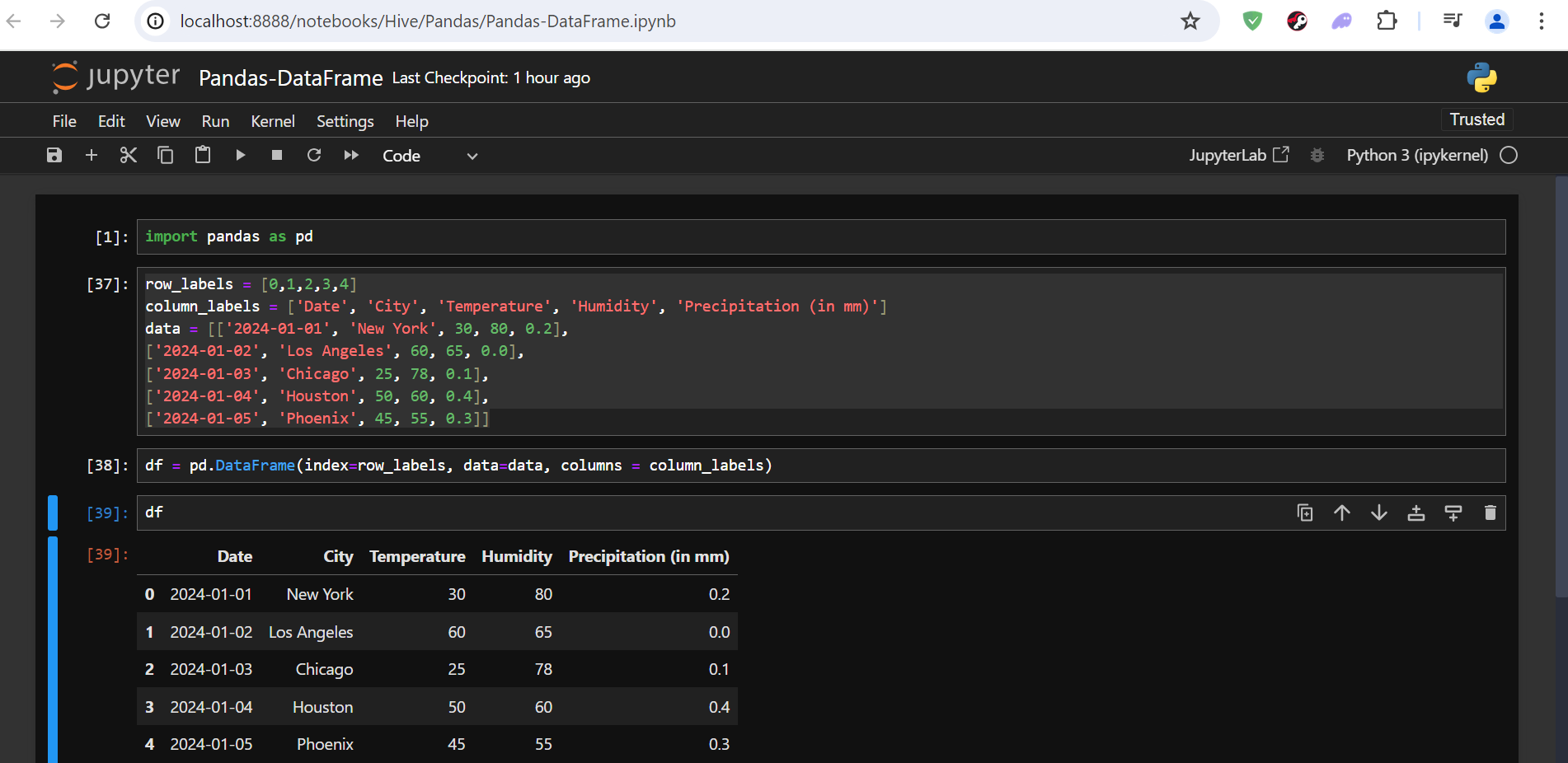
For the data, you can pass it any format like you want. I had passed the data in nested list form but you can pass set, tuple as you like and it will still return the same result. Now, you can see the index to be 0 till 5. I want the city to be index. We can do it by:
```
df.set_index("City")
```
If you run the above code, you will get following output:
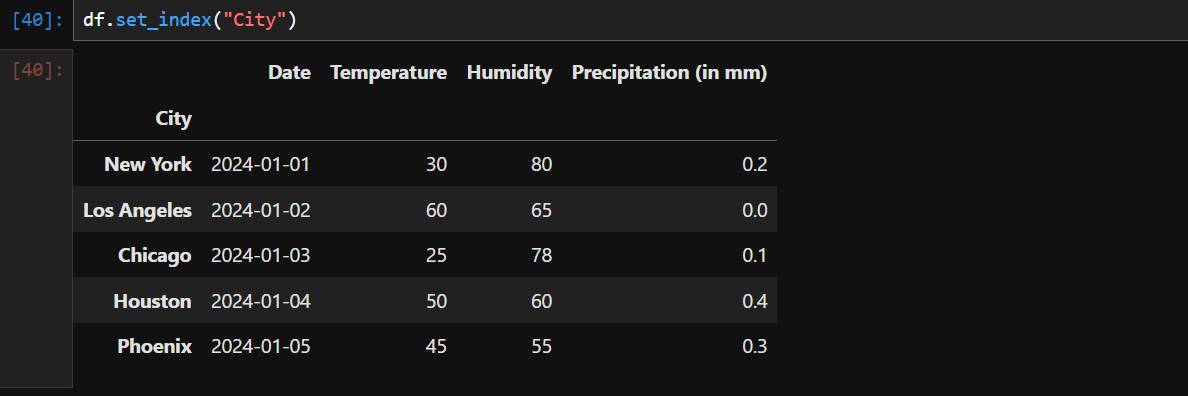
Note that specifying index like this won't change the original dataframe with city being the index. If you print your dataframe after doing this, you will get the original dataframe like below:
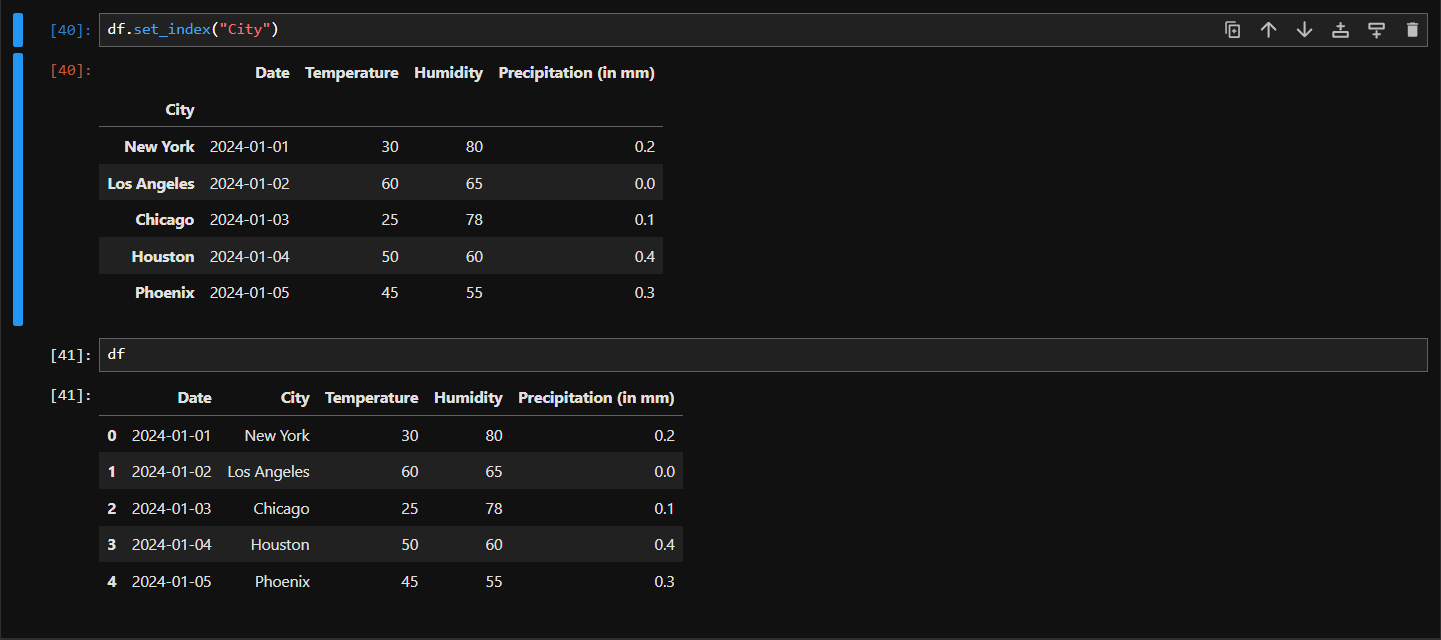
In order to actually apply the change to the original dataframe there is optional argument that you can pass to **set_index()** function which is as below:
```
df.set_index("City", inplace=True)
df
```
Now you can see your desired output like below:
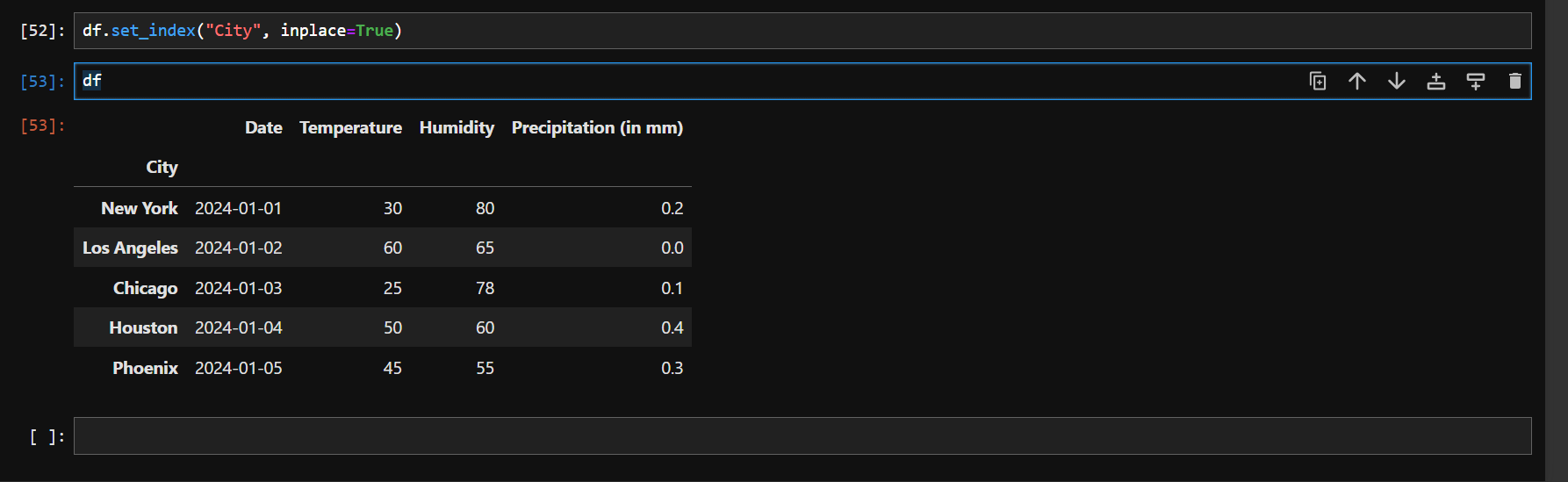
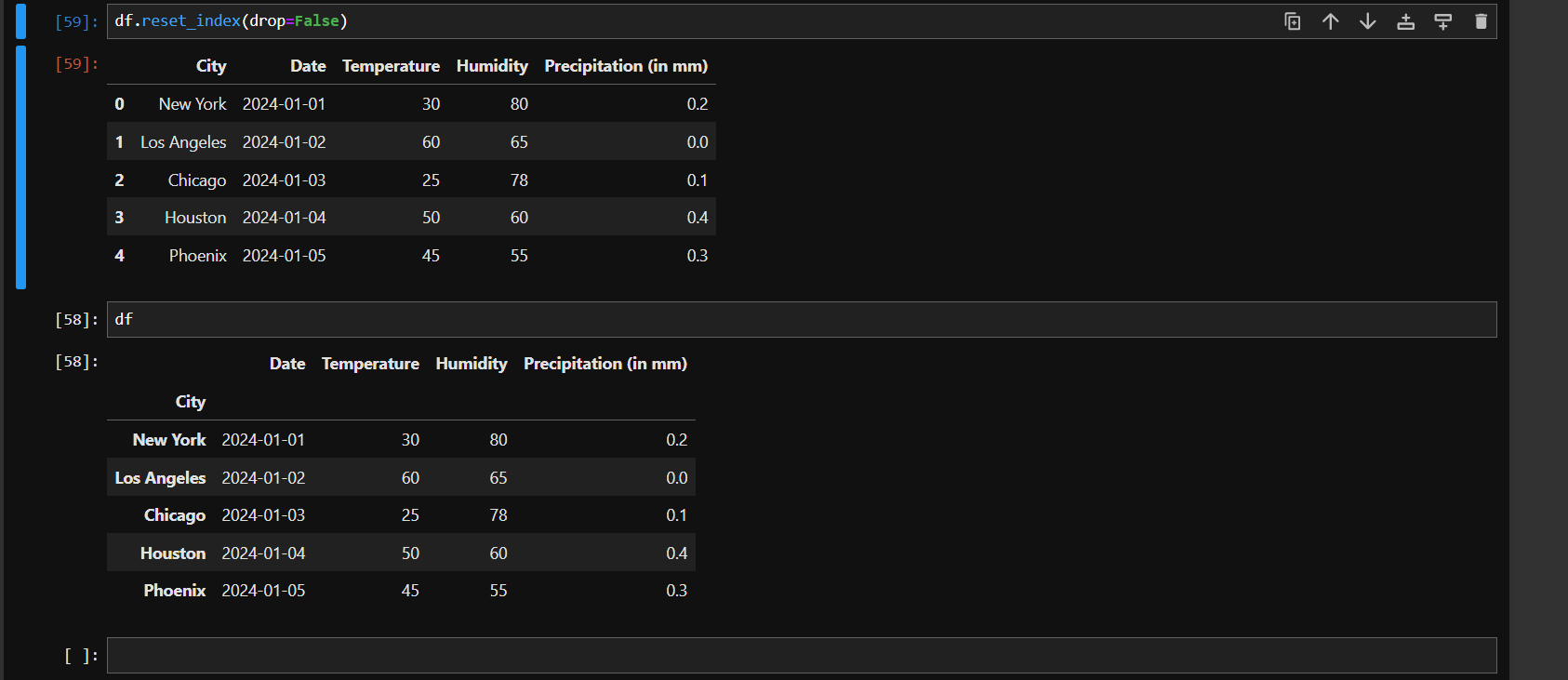
by default **inplace** value is set to false. There is also other optional argument called **drop** which is by default set to True. When you set it to False, then the City label will stay there as it was previously and as an index as well. You can reset the index by using `reset_index` method as below:
```
df.reset_index(drop=False)
```
If you don't set `drop=False` then city will be dropped and we won't get back our original dataframe. The output of above code is:
So that's all for now regarding basic of pandas dataframe. From next post, we will talk about reading CSV files using pandas and further posts will discuss about manipulating data using pandas library.
</div>| author | leoumesh | ||||||
|---|---|---|---|---|---|---|---|
| permlink | pandas-dataframe | ||||||
| category | hive-196387 | ||||||
| json_metadata | {"app":"peakd/2024.7.2","format":"markdown","tags":["stem","python","code","coding","computerscience","tutorial","programming","pandas"],"users":["leoumesh"],"image":["https://files.peakd.com/file/peakd-hive/leoumesh/23tvgY6dGorMvqefy5UBPxo45YUFX5U6qw74e2uktdJUHf29T3foUNkuPdcCjFJhnM815.png","https://files.peakd.com/file/peakd-hive/leoumesh/23xA22yY3CfUffLoUYeW3wSZCptGtgWrg4i6pUdG8SksK96JnsP1Le6j7am6ey4D2RYkD.png","https://files.peakd.com/file/peakd-hive/leoumesh/23t74pDhgCaPBrCSYHQ7AK9GLFivwu64ie8aHxUDkibgqqkCuRWWCY4wb5pAHyysaCwN5.png","https://files.peakd.com/file/peakd-hive/leoumesh/23t732e3F9fabxETC4p3dMyoQeS4RQ9bwdEsMXnHjdbSoJEEviVCR4DpKkX3NEQXPyinT.png","https://files.peakd.com/file/peakd-hive/leoumesh/23sweHpQsMV4qpay3N2gVDyVnfZeSV9TbTQhReuVXYF2W9YY6yLvjSsDBd6rNQ9Bu51fe.png","https://files.peakd.com/file/peakd-hive/leoumesh/23t72QtMNBoB8Jyfk9HTnWoa9o2iN7g9pWDVe3wxFnM1ToBzsCJwXapnggMUEThxwJAj3.png"]} | ||||||
| created | 2024-07-19 04:12:36 | ||||||
| last_update | 2024-07-19 04:12:36 | ||||||
| depth | 0 | ||||||
| children | 3 | ||||||
| last_payout | 2024-07-26 04:12:36 | ||||||
| cashout_time | 1969-12-31 23:59:59 | ||||||
| total_payout_value | 2.290 HBD | ||||||
| curator_payout_value | 2.367 HBD | ||||||
| pending_payout_value | 0.000 HBD | ||||||
| promoted | 0.000 HBD | ||||||
| body_length | 4,660 | ||||||
| author_reputation | 212,340,493,251,438 | ||||||
| root_title | "Pandas DataFrame" | ||||||
| beneficiaries |
| ||||||
| max_accepted_payout | 1,000,000.000 HBD | ||||||
| percent_hbd | 10,000 | ||||||
| post_id | 135,383,260 | ||||||
| net_rshares | 14,730,738,060,527 | ||||||
| author_curate_reward | "" |
| voter | weight | wgt% | rshares | pct | time |
|---|---|---|---|---|---|
| kevinwong | 0 | 1,225,951,074 | 0.6% | ||
| eric-boucher | 0 | 3,339,350,709 | 0.6% | ||
| roelandp | 0 | 116,969,753,745 | 7.5% | ||
| cloh76 | 0 | 824,659,959 | 0.6% | ||
| logic | 0 | 175,394,548,691 | 100% | ||
| sunshine | 0 | 43,437,752,652 | 7.5% | ||
| lemouth | 0 | 441,642,784,134 | 15% | ||
| netaterra | 0 | 6,402,983,836 | 0.6% | ||
| tfeldman | 0 | 1,138,977,608 | 0.6% | ||
| metabs | 0 | 1,632,291,877 | 15% | ||
| mcsvi | 0 | 93,933,533,014 | 50% | ||
| cnfund | 0 | 2,686,708,129 | 1.2% | ||
| boxcarblue | 0 | 3,124,712,793 | 0.6% | ||
| steemcleaners | 0 | 2,359,452,362,970 | 80% | ||
| justyy | 0 | 10,116,416,947 | 1.2% | ||
| michelle.gent | 0 | 715,850,579 | 0.24% | ||
| curie | 0 | 80,465,381,172 | 1.2% | ||
| modernzorker | 0 | 850,327,825 | 0.84% | ||
| techslut | 0 | 40,361,317,740 | 6% | ||
| steemstem | 0 | 280,391,572,120 | 15% | ||
| edb | 0 | 1,364,143,590 | 1.5% | ||
| yadamaniart | 0 | 882,701,852 | 0.6% | ||
| walterjay | 0 | 84,941,863,782 | 7.5% | ||
| valth | 0 | 11,401,113,669 | 7.5% | ||
| metroair | 0 | 6,270,143,387 | 1.2% | ||
| voter | 0 | 3,781,687,469 | 100% | ||
| dna-replication | 0 | 548,729,435 | 15% | ||
| dhimmel | 0 | 81,499,694,267 | 3.75% | ||
| oluwatobiloba | 0 | 492,272,790 | 15% | ||
| elevator09 | 0 | 3,237,757,706 | 0.6% | ||
| detlev | 0 | 6,250,408,332 | 0.36% | ||
| federacion45 | 0 | 1,801,393,519 | 0.6% | ||
| gamersclassified | 0 | 1,127,723,086 | 0.6% | ||
| mvd | 0 | 549,021,677 | 50% | ||
| forykw | 0 | 3,035,771,114 | 0.6% | ||
| mobbs | 0 | 44,439,743,126 | 15% | ||
| jerrybanfield | 0 | 4,573,802,858 | 1.2% | ||
| rt395 | 0 | 2,258,192,503 | 1.5% | ||
| bitrocker2020 | 0 | 2,459,754,825 | 0.24% | ||
| sustainablyyours | 0 | 4,515,457,856 | 7.5% | ||
| juancar347 | 0 | 3,800,679,692 | 0.6% | ||
| samminator | 0 | 8,670,990,791 | 7.5% | ||
| enjar | 0 | 10,832,614,169 | 1.08% | ||
| mahdiyari | 0 | 969,758,974,665 | 80% | ||
| lorenzor | 0 | 1,356,782,769 | 50% | ||
| firstamendment | 0 | 94,248,568,382 | 50% | ||
| ewkaw | 0 | 632,366,336,864 | 20% | ||
| alexander.alexis | 0 | 9,177,815,665 | 15% | ||
| jayna | 0 | 1,610,984,743 | 0.24% | ||
| princessmewmew | 0 | 1,739,794,733 | 0.6% | ||
| joeyarnoldvn | 0 | 464,894,128 | 1.47% | ||
| ufv | 0 | 3,006,808,420 | 50% | ||
| gunthertopp | 0 | 15,207,618,858 | 0.3% | ||
| pipiczech | 0 | 509,616,160 | 1.2% | ||
| empath | 0 | 901,662,377 | 0.6% | ||
| eturnerx | 0 | 20,923,103,332 | 1.9% | ||
| dante31 | 0 | 1,918,486,300 | 55% | ||
| minnowbooster | 0 | 837,260,531,082 | 20% | ||
| felt.buzz | 0 | 1,718,847,178 | 0.3% | ||
| howo | 0 | 452,496,016,778 | 15% | ||
| tsoldovieri | 0 | 1,556,188,286 | 7.5% | ||
| neumannsalva | 0 | 1,049,832,707 | 0.6% | ||
| stayoutoftherz | 0 | 31,867,269,781 | 0.3% | ||
| abigail-dantes | 0 | 5,794,682,867 | 15% | ||
| coindevil | 0 | 605,301,948 | 0.96% | ||
| zonguin | 0 | 768,184,767 | 3.75% | ||
| investingpennies | 0 | 4,001,817,593 | 1.2% | ||
| iamphysical | 0 | 1,537,150,711 | 90% | ||
| aaronleang | 0 | 9,862,475,546 | 20% | ||
| zyx066 | 0 | 749,220,382 | 0.36% | ||
| revo | 0 | 2,773,683,340 | 1.2% | ||
| azulear | 0 | 1,417,500,195 | 100% | ||
| psicoluigi | 0 | 819,136,018 | 50% | ||
| spaminator | 0 | 2,718,402,071,229 | 100% | ||
| rocky1 | 0 | 168,383,191,351 | 0.18% | ||
| thelordsharvest | 0 | 550,383,312 | 1.2% | ||
| aidefr | 0 | 1,733,491,015 | 7.5% | ||
| tomiscurious | 0 | 217,998,712,123 | 38.9% | ||
| sorin.cristescu | 0 | 41,612,037,394 | 7.5% | ||
| futurethinker | 0 | 1,480,972,510 | 100% | ||
| podanrj | 0 | 1,216,488,645 | 55% | ||
| fatman | 0 | 9,074,205,265 | 2% | ||
| votehero | 0 | 21,500,489,154 | 4.6% | ||
| inthenow | 0 | 22,687,266,266 | 20% | ||
| splash-of-angs63 | 0 | 12,285,989,624 | 50% | ||
| sharpshot | 0 | 109,647,032,638 | 40% | ||
| deadzy | 0 | 563,390,350 | 40% | ||
| meno | 0 | 7,713,044,340 | 0.6% | ||
| technicalside | 0 | 7,784,540,633 | 25% | ||
| enzor | 0 | 924,404,805 | 15% | ||
| bartosz546 | 0 | 4,314,186,794 | 0.6% | ||
| dreamm | 0 | 3,268,074,011 | 50% | ||
| sunsea | 0 | 1,628,428,783 | 0.6% | ||
| postpromoter | 0 | 484,760,391,265 | 15% | ||
| bluefinstudios | 0 | 865,916,250 | 0.36% | ||
| steveconnor | 0 | 1,076,932,628 | 0.6% | ||
| dbddv01 | 0 | 513,857,925 | 3.75% | ||
| nicole-st | 0 | 603,455,506 | 0.6% | ||
| aboutcoolscience | 0 | 9,491,302,011 | 15% | ||
| amestyj | 0 | 76,531,417,685 | 100% | ||
| sandracarrascal | 0 | 513,855,685 | 50% | ||
| kenadis | 0 | 4,070,473,277 | 15% | ||
| madridbg | 0 | 5,380,290,077 | 15% | ||
| robotics101 | 0 | 4,738,715,849 | 15% | ||
| lpv | 0 | 611,693,405 | 1.87% | ||
| gentleshaid | 0 | 2,174,050,966 | 7.5% | ||
| adelepazani | 0 | 481,917,323 | 0.24% | ||
| duke77 | 0 | 1,255,544,056 | 40% | ||
| r00sj3 | 0 | 23,532,301,812 | 7.5% | ||
| sco | 0 | 4,848,209,632 | 15% | ||
| ennyta | 0 | 993,997,127 | 50% | ||
| juecoree | 0 | 932,118,504 | 10.5% | ||
| gabrielatravels | 0 | 549,998,227 | 0.42% | ||
| eliaschess333 | 0 | 13,944,358,594 | 100% | ||
| bartheek | 0 | 807,513,216 | 1.2% | ||
| hetty-rowan | 0 | 1,303,925,332 | 0.6% | ||
| ydavgonzalez | 0 | 1,748,727,956 | 10% | ||
| intrepidphotos | 0 | 3,821,283,681 | 11.25% | ||
| fineartnow | 0 | 844,072,447 | 0.6% | ||
| hijosdelhombre | 0 | 53,572,628,264 | 40% | ||
| oscarina | 0 | 755,575,213 | 10% | ||
| aiziqi | 0 | 1,086,361,078 | 5% | ||
| steemvault | 0 | 469,455,602 | 1.2% | ||
| communitybank | 0 | 792,771,320 | 1.2% | ||
| fragmentarion | 0 | 3,521,365,197 | 15% | ||
| osarueseosato | 0 | 668,811,237 | 100% | ||
| utube | 0 | 818,817,086 | 1.2% | ||
| m1alsan | 0 | 1,069,258,831 | 1.2% | ||
| neneandy | 0 | 1,349,316,756 | 1.2% | ||
| marc-allaria | 0 | 53,555,937,421 | 40% | ||
| sportscontest | 0 | 1,227,810,096 | 1.2% | ||
| gribouille | 0 | 696,255,770 | 15% | ||
| itharagaian | 0 | 5,336,661,338 | 40% | ||
| pandasquad | 0 | 3,261,987,466 | 1.2% | ||
| leoumesh | 0 | 1,755,121,924 | 100% | ||
| miguelangel2801 | 0 | 796,864,349 | 50% | ||
| mproxima | 0 | 467,453,267 | 0.6% | ||
| fantasycrypto | 0 | 794,763,381 | 1.2% | ||
| careassaktart | 0 | 513,945,716 | 1.2% | ||
| emiliomoron | 0 | 1,354,152,472 | 7.5% | ||
| dexterdev | 0 | 579,532,582 | 7.5% | ||
| photohunt | 0 | 716,508,742 | 1.2% | ||
| geopolis | 0 | 964,427,925 | 15% | ||
| robertbira | 0 | 1,585,740,794 | 3.75% | ||
| alexdory | 0 | 1,998,874,451 | 15% | ||
| irgendwo | 0 | 5,079,639,116 | 1.2% | ||
| charitybot | 0 | 5,135,816,697 | 100% | ||
| cyprianj | 0 | 7,951,993,081 | 15% | ||
| promo-mentors | 0 | 712,309,328 | 100% | ||
| melvin7 | 0 | 24,549,684,612 | 7.5% | ||
| francostem | 0 | 2,050,909,145 | 15% | ||
| endopediatria | 0 | 695,806,150 | 20% | ||
| croctopus | 0 | 1,521,717,162 | 100% | ||
| putu300 | 0 | 803,041,752 | 5% | ||
| michelmake | 0 | 42,632,488,857 | 20% | ||
| zipporah | 0 | 582,314,419 | 0.24% | ||
| superlotto | 0 | 1,558,690,664 | 1.2% | ||
| satren | 0 | 12,125,994,488 | 10% | ||
| bscrypto | 0 | 3,328,881,086 | 0.6% | ||
| movingman | 0 | 583,225,459 | 20% | ||
| delpilar | 0 | 934,959,443 | 25% | ||
| tomastonyperez | 0 | 17,118,554,130 | 50% | ||
| bil.prag | 0 | 497,716,984 | 0.06% | ||
| elvigia | 0 | 11,062,835,410 | 50% | ||
| sanderjansenart | 0 | 1,227,860,738 | 0.6% | ||
| laxam | 0 | 5,755,963,895 | 100% | ||
| qberry | 0 | 861,777,867 | 0.6% | ||
| greddyforce | 0 | 1,003,583,432 | 0.44% | ||
| racibo | 0 | 18,279,063,308 | 20% | ||
| melbourneswest | 0 | 794,627,423 | 0.6% | ||
| gadrian | 0 | 142,317,305,799 | 11.25% | ||
| therising | 0 | 25,223,771,183 | 1.2% | ||
| gifty-e | 0 | 590,550,614 | 80% | ||
| scruffy23 | 0 | 20,145,873,074 | 50% | ||
| de-stem | 0 | 8,245,951,615 | 14.85% | ||
| serylt | 0 | 654,266,265 | 14.7% | ||
| josedelacruz | 0 | 4,224,899,145 | 50% | ||
| kgakakillerg | 0 | 20,426,639,098 | 10% | ||
| charitymemes | 0 | 523,743,093 | 100% | ||
| softa | 0 | 753,369,620 | 0.24% | ||
| realblockchain | 0 | 16,778,703,017 | 50% | ||
| erickyoussif | 0 | 660,653,838 | 100% | ||
| meanbees | 0 | 27,326,386,483 | 25% | ||
| primersion | 0 | 436,960,618,144 | 20% | ||
| deholt | 0 | 838,436,460 | 12.75% | ||
| robmolecule | 0 | 23,614,669,617 | 10% | ||
| studio666 | 0 | 3,043,588,335 | 100% | ||
| anneporter | 0 | 548,129,272 | 4.5% | ||
| pladozero | 0 | 31,453,045,511 | 10% | ||
| minerthreat | 0 | 822,498,979 | 0.6% | ||
| nateaguila | 0 | 70,906,969,181 | 5% | ||
| temitayo-pelumi | 0 | 1,402,254,536 | 15% | ||
| andrick | 0 | 866,365,209 | 50% | ||
| doctor-cog-diss | 0 | 14,878,266,018 | 15% | ||
| marcuz | 0 | 559,244,318 | 7.5% | ||
| vinzie1 | 0 | 9,011,302,224 | 3% | ||
| acont | 0 | 1,830,636,054 | 50% | ||
| uche-nna | 0 | 1,792,081,959 | 0.96% | ||
| drawmeaship | 0 | 1,353,491,608 | 50% | ||
| citizendog | 0 | 559,346,751 | 1.2% | ||
| letenebreux | 0 | 1,451,649,333 | 40% | ||
| wittywheat | 0 | 40,368,485,972 | 100% | ||
| cheese4ead | 0 | 926,602,866 | 0.6% | ||
| apshamilton | 0 | 2,789,385,330 | 0.15% | ||
| cryptojiang | 0 | 142,681,602,489 | 100% | ||
| nattybongo | 0 | 5,965,420,179 | 15% | ||
| talentclub | 0 | 771,740,769 | 0.6% | ||
| bflanagin | 0 | 746,659,414 | 0.6% | ||
| ubaldonet | 0 | 2,573,755,525 | 80% | ||
| armandosodano | 0 | 797,006,639 | 0.6% | ||
| acousticguitar | 0 | 14,194,234,751 | 50% | ||
| hamismsf | 0 | 988,069,671 | 0.15% | ||
| gerdtrudroepke | 0 | 38,015,809,371 | 10.5% | ||
| goblinknackers | 0 | 80,220,449,564 | 7% | ||
| anttn | 0 | 6,857,853,823 | 20% | ||
| reinaseq | 0 | 8,118,054,672 | 100% | ||
| kylealex | 0 | 5,347,401,090 | 10% | ||
| orlandogonzalez | 0 | 2,929,146,043 | 25% | ||
| fran.frey | 0 | 4,214,477,344 | 50% | ||
| pboulet | 0 | 33,880,770,514 | 12% | ||
| cercle | 0 | 2,162,562,317 | 40% | ||
| stem-espanol | 0 | 2,222,132,271 | 100% | ||
| voter001 | 0 | 21,449,836,235 | 24.1% | ||
| futurekr | 0 | 2,394,698,080 | 100% | ||
| cliffagreen | 0 | 5,013,602,967 | 10% | ||
| aleestra | 0 | 14,951,463,379 | 80% | ||
| palasatenea | 0 | 729,154,931 | 0.6% | ||
| the.success.club | 0 | 723,788,188 | 0.6% | ||
| amansharma555 | 0 | 595,961,049 | 100% | ||
| brianoflondon | 0 | 20,030,954,670 | 0.3% | ||
| giulyfarci52 | 0 | 1,722,948,742 | 50% | ||
| esthersanchez | 0 | 3,857,856,608 | 60% | ||
| kristall97 | 0 | 765,302,377 | 100% | ||
| steemcryptosicko | 0 | 2,004,764,764 | 0.24% | ||
| multifacetas | 0 | 500,163,171 | 0.6% | ||
| cakemonster | 0 | 597,161,449 | 1.2% | ||
| stem.witness | 0 | 877,070,121 | 15% | ||
| hiddendragon | 0 | 649,894,648 | 38% | ||
| chipdip | 0 | 820,265,815 | 10% | ||
| jpbliberty | 0 | 1,849,729,171 | 0.3% | ||
| double-negative | 0 | 527,246,754 | 20% | ||
| priyandaily | 0 | 3,081,975,289 | 40% | ||
| vaultec | 0 | 4,420,988,023 | 12% | ||
| steemstorage | 0 | 1,456,539,177 | 1.2% | ||
| aqua.nano | 0 | 536,321,594 | 100% | ||
| crowdwitness | 0 | 4,829,413,627 | 7.5% | ||
| hairgistix | 0 | 680,686,819 | 0.6% | ||
| steemean | 0 | 10,097,100,103 | 5% | ||
| hashkings | 0 | 22,745,203,472 | 25% | ||
| littlesorceress | 0 | 496,713,020 | 0.6% | ||
| newton666 | 0 | 3,786,587,407 | 100% | ||
| aaronkroeblinger | 0 | 117,982,701,522 | 50% | ||
| cryptofiloz | 0 | 1,936,531,953 | 1.2% | ||
| eliana-art | 0 | 1,064,307,267 | 100% | ||
| akumagai | 0 | 36,776,051,209 | 100% | ||
| qwerrie | 0 | 1,155,617,194 | 0.09% | ||
| tinyhousecryptos | 0 | 473,949,914 | 5% | ||
| walterprofe | 0 | 754,770,900 | 7.5% | ||
| reggaesteem | 0 | 501,020,052 | 5% | ||
| alypanda | 0 | 674,097,176 | 100% | ||
| tokensink | 0 | 692,594,681 | 1.2% | ||
| beta500 | 0 | 803,419,964 | 1.2% | ||
| nazer | 0 | 478,648,314 | 7.5% | ||
| elianaicgomes | 0 | 4,351,016,295 | 5% | ||
| pal.alfa | 0 | 6,602,913,992 | 100% | ||
| stem.alfa | 0 | 3,288,206,274 | 100% | ||
| madisonelizabeth | 0 | 647,445,806 | 100% | ||
| steemstem-trig | 0 | 274,477,200 | 15% | ||
| baltai | 0 | 1,609,206,408 | 0.6% | ||
| ibt-survival | 0 | 38,496,651,087 | 10% | ||
| manic.calm | 0 | 9,637,710,688 | 100% | ||
| hive-199963 | 0 | 752,098,429 | 1.2% | ||
| fsm-core | 0 | 12,721,780,367 | 50% | ||
| hivewatchers | 0 | 1,937,694,529 | 55% | ||
| thepeakstudio | 0 | 2,803,268,445 | 100% | ||
| stemsocial | 0 | 127,838,196,512 | 15% | ||
| kyleana | 0 | 1,812,780,543 | 50% | ||
| veeart | 0 | 2,372,195,448 | 50% | ||
| hive-143869 | 0 | 303,322,100,036 | 40% | ||
| hivelist | 0 | 1,978,000,782 | 0.36% | ||
| kiemurainen | 0 | 2,324,187,806 | 0.5% | ||
| noelyss | 0 | 3,495,823,705 | 7.5% | ||
| kingfadino | 0 | 51,011,830,138 | 50% | ||
| miguelpeliculas | 0 | 2,772,500,658 | 40% | ||
| dobro2020 | 0 | 8,757,594,715 | 100% | ||
| quinnertronics | 0 | 10,431,939,816 | 7% | ||
| mercurial9 | 0 | 28,264,764,054 | 100% | ||
| portsundries | 0 | 2,761,652,796 | 100% | ||
| dani.romero96 | 0 | 2,238,145,752 | 40% | ||
| altleft | 0 | 5,113,624,846 | 0.01% | ||
| mattbee | 0 | 612,836,488 | 100% | ||
| apendix1994 | 0 | 4,022,553,031 | 90% | ||
| emeraldtiger | 0 | 3,297,392,725 | 20% | ||
| meritocracy | 0 | 13,525,448,590 | 0.12% | ||
| jmsansan | 0 | 942,554,314 | 0.6% | ||
| pepeymeli | 0 | 789,493,210 | 50% | ||
| he-index | 0 | 14,885,385,186 | 10% | ||
| dcrops | 0 | 9,296,795,391 | 0.6% | ||
| rondonshneezy | 0 | 2,528,985,994 | 12.5% | ||
| hive-129556 | 0 | 2,316,832,595 | 100% | ||
| entraide.rewards | 0 | 1,268,105,950 | 40% | ||
| peerfinance | 0 | 42,808,988,863 | 100% | ||
| hive-126300 | 0 | 489,359,130 | 100% | ||
| eturnerx-dbuzz | 0 | 21,657,625,253 | 65.8% | ||
| cookaiss | 0 | 3,704,349,718 | 20% | ||
| tawadak24 | 0 | 817,756,909 | 0.6% | ||
| farleyfund | 0 | 6,453,525,575 | 100% | ||
| failingforwards | 0 | 758,473,014 | 0.6% | ||
| drricksanchez | 0 | 3,273,788,598 | 0.6% | ||
| high8125theta | 0 | 47,845,306,903 | 60% | ||
| nfttunz | 0 | 2,180,154,932 | 0.12% | ||
| okluvmee | 0 | 1,031,302,707 | 0.6% | ||
| merit.ahama | 0 | 1,232,435,244 | 0.36% | ||
| holovision.cash | 0 | 3,383,254,700 | 100% | ||
| holovision.stem | 0 | 1,713,598,151 | 100% | ||
| sarashew | 0 | 438,921,810 | 1.2% | ||
| podping | 0 | 1,952,708,532 | 0.3% | ||
| t-nil | 0 | 591,056,777 | 10% | ||
| pinkfloyd878 | 0 | 5,667,854,461 | 100% | ||
| irivers | 0 | 0 | 100% | ||
| funshee | 0 | 1,161,348,084 | 6% | ||
| wongi | 0 | 6,316,159,382 | 10% | ||
| tanzil2024 | 0 | 1,874,738,545 | 1% | ||
| sidalim88 | 0 | 702,328,771 | 0.6% | ||
| aries90 | 0 | 11,785,306,679 | 1.2% | ||
| migka | 0 | 5,121,278,855 | 90% | ||
| blingit | 0 | 764,573,613 | 0.6% | ||
| yixn | 0 | 2,893,502,710 | 0.6% | ||
| hiveborgminer | 0 | 7,958,518,812 | 100% | ||
| academician | 0 | 701,472,856,690 | 100% | ||
| newilluminati | 0 | 3,492,190,809 | 0.6% | ||
| lichtkunstfoto | 0 | 1,777,007,042 | 1.2% | ||
| marlonfund | 0 | 1,098,697,548 | 100% | ||
| vindiesel1980 | 0 | 1,706,577,354 | 0.6% | ||
| hislab | 0 | 777,134,268 | 70% | ||
| sam9999 | 0 | 1,265,039,201 | 7.5% | ||
| benwickenton | 0 | 647,073,873 | 1.2% | ||
| blackdaisyft | 0 | 19,349,266,600 | 50% | ||
| azj26 | 0 | 4,601,577,176 | 16% | ||
| prosocialise | 0 | 34,267,293,249 | 7.5% | ||
| archangel21 | 0 | 3,698,226,098 | 1.2% | ||
| belug | 0 | 1,429,285,810 | 0.36% | ||
| independance | 0 | 5,284,143,031 | 40% | ||
| mugueto2022 | 0 | 560,528,506 | 20% | ||
| isiksenpalvoja | 0 | 1,211,731,452 | 40% | ||
| kryptofire | 0 | 3,067,730,525 | 20% | ||
| mr-rent | 0 | 4,288,074,211 | 75% | ||
| soyjoselopez | 0 | 472,991,511 | 20% | ||
| quduus1 | 0 | 4,554,545,004 | 10% | ||
| hk-curation | 0 | 61,752,839,638 | 50% | ||
| cindynancy | 0 | 742,487,422 | 7.5% | ||
| graciousvic | 0 | 920,342,519 | 10% | ||
| lordnight72 | 0 | 558,529,405 | 40% | ||
| clavdio75 | 0 | 754,061,975 | 12% | ||
| smariam | 0 | 2,855,248,449 | 25% | ||
| hive-fr | 0 | 767,947,861 | 40% | ||
| clpacksperiment | 0 | 583,245,238 | 0.6% | ||
| hive-189277 | 0 | 3,201,872,018 | 20% | ||
| humbe | 0 | 5,956,209,427 | 2% | ||
| dresden.theone | 0 | 1,344,995,746 | 0.6% | ||
| sapphireleopard | 0 | 731,971,152 | 40% | ||
| opticus | 0 | 6,953,609,080 | 1.2% | ||
| unity-freedom | 0 | 1,712,625,391 | 20% | ||
| rhemagames | 0 | 1,124,875,830 | 0.6% | ||
| soylegionario | 0 | 989,953,675 | 1.2% | ||
| anttn.support | 0 | 647,540,046 | 20% | ||
| kryptof | 0 | 8,371,168,746 | 15% | ||
| nabab | 0 | 470,099,399 | 40% | ||
| oladamola | 0 | 23,195,293,203 | 20% | ||
| skm74 | 0 | 2,810,611,899 | 100% | ||
| meta-etre | 0 | 2,774,974,028 | 40% | ||
| profwhitetower | 0 | 25,856,124 | 100% | ||
| vmihalache | 0 | 1,480,129,754 | 0.6% | ||
| bostonadventures | 0 | 1,247,007,206 | 0.6% |
it is good example of how do tables with python but it is better sql :D
| author | dobro2020 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| permlink | sgvq29 | ||||||||||||
| category | hive-196387 | ||||||||||||
| json_metadata | {"app":"hiveblog/0.1"} | ||||||||||||
| created | 2024-07-19 16:35:00 | ||||||||||||
| last_update | 2024-07-19 16:35:00 | ||||||||||||
| depth | 1 | ||||||||||||
| children | 1 | ||||||||||||
| last_payout | 2024-07-26 16:35:00 | ||||||||||||
| cashout_time | 1969-12-31 23:59:59 | ||||||||||||
| total_payout_value | 0.000 HBD | ||||||||||||
| curator_payout_value | 0.000 HBD | ||||||||||||
| pending_payout_value | 0.000 HBD | ||||||||||||
| promoted | 0.000 HBD | ||||||||||||
| body_length | 71 | ||||||||||||
| author_reputation | 66,734,662,885,414 | ||||||||||||
| root_title | "Pandas DataFrame" | ||||||||||||
| beneficiaries |
| ||||||||||||
| max_accepted_payout | 1,000,000.000 HBD | ||||||||||||
| percent_hbd | 10,000 | ||||||||||||
| post_id | 135,393,235 | ||||||||||||
| net_rshares | 0 |
Both of them excel at their own purpose. SQL is better used for extracting and filtering while pandas is better used for manipulation.
| author | leoumesh |
|---|---|
| permlink | sgyyvq |
| category | hive-196387 |
| json_metadata | {"app":"hiveblog/0.1"} |
| created | 2024-07-21 10:38:42 |
| last_update | 2024-07-21 10:38:42 |
| depth | 2 |
| children | 0 |
| last_payout | 2024-07-28 10:38:42 |
| cashout_time | 1969-12-31 23:59:59 |
| total_payout_value | 0.000 HBD |
| curator_payout_value | 0.000 HBD |
| pending_payout_value | 0.000 HBD |
| promoted | 0.000 HBD |
| body_length | 134 |
| author_reputation | 212,340,493,251,438 |
| root_title | "Pandas DataFrame" |
| beneficiaries | [] |
| max_accepted_payout | 1,000,000.000 HBD |
| percent_hbd | 10,000 |
| post_id | 135,439,207 |
| net_rshares | 0 |
<div class='text-justify'> <div class='pull-left'> <img src='https://stem.openhive.network/images/stemsocialsupport7.png'> </div> Thanks for your contribution to the <a href='/trending/hive-196387'>STEMsocial community</a>. Feel free to join us on <a href='https://discord.gg/9c7pKVD'>discord</a> to get to know the rest of us! Please consider delegating to the @stemsocial account (85% of the curation rewards are returned). Thanks for including @stemsocial as a beneficiary, which gives you stronger support. <br /> <br /> </div>
| author | stemsocial |
|---|---|
| permlink | re-leoumesh-pandas-dataframe-20240719t050324927z |
| category | hive-196387 |
| json_metadata | {"app":"STEMsocial"} |
| created | 2024-07-19 05:03:24 |
| last_update | 2024-07-19 05:03:24 |
| depth | 1 |
| children | 0 |
| last_payout | 2024-07-26 05:03:24 |
| cashout_time | 1969-12-31 23:59:59 |
| total_payout_value | 0.000 HBD |
| curator_payout_value | 0.000 HBD |
| pending_payout_value | 0.000 HBD |
| promoted | 0.000 HBD |
| body_length | 545 |
| author_reputation | 22,927,767,309,334 |
| root_title | "Pandas DataFrame" |
| beneficiaries | [] |
| max_accepted_payout | 1,000,000.000 HBD |
| percent_hbd | 10,000 |
| post_id | 135,383,781 |
| net_rshares | 0 |